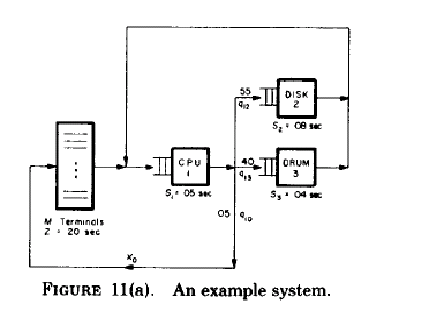
I wrote to the authors of “Scaling Architecture Evaluations Within Real-World Constraints” about my interest in finding reference material for the various Software Architecture evaluation methods like ATAM, CBAM etc.
One of the authors, Zhao li, responded with a rather large list of references. I have not read all of them. Now that I have found references I am searching for companies that actualy use one or many of them !!
Scenario-based Architecture Evaluation
| ALMA |
Architecture Level Modifiability Analysis [32] |
| ALPSM |
Architecture Level Prediction of Software Maintenance [33] |
| ATAM |
Architecture Trade-Off Analysis Method [13] |
| ARID |
Active Review for Intermediate Design [21] |
| CBAM |
Cost Benefit Analysis Method [22] |
| CPASA |
Continuous Performance Assessment of Software Architecture [23] |
| ESAAMI |
Extending SAAM by Integration in the Domain [19] |
| HoPLAA |
TAM for Production Line Analysis [20] |
| SAAM |
Scenario-based Architecture Analysis Method [15] |
| SAAMCS SAAM |
Founded on Complex Scenarios [18] |
| SAAMER |
Software Architecture Analysis Method for Evolution and Reusability [34] |
| SALUTA |
Scenario-based Architecture Level Usability Analysis [35] |
| AHP |
Analytic hierarchy process [28] |
Attribute-based Software Architecture Evaluation
| ALRRA |
Architecture Level Reliability Risk Analysis [29] |
| PASA |
Performance Assessment of Software Architectures [10] |
| SAEM |
Software Architecture Evaluation Model [9] |
| SAABNet |
Software Architecture Evaluation Model [11] |
| SACMM |
Metrics of Software Architecture Changes based on Structural Metrics [27] |
| SASAM |
Static Evaluation of Software Architecture [25] |
Others
| ISAR |
Independent Software Architecture Review [24] |
| GQM |
Application of Goal/Question/Metric framework on SA [26] |
| LAAAM |
Lightweight Architecture Alternative Analysis Method [30] |
| TARA |
Tiny Architecture Review Approach [31] |
REFERENCES
1. L. Bass, P. Clements, and R. Kazman, “Software Architecture in Practice.” Addison-Wesley, 1998
2. W. Li and S. Henry, “Object-Oriented Metrics that Predict Maintainability,” J. Systems and Software, vol. 23, no. 2. pp. 111-122, Nov. 1993.
3. L. Dobrica and E. Niemela, “A Survey on Software Architecture Analysis Methods”, IEEE Transactions on Software Engineering, Vol. 28, No. 7, July 2002
4. Y. Chen, X. Li, L. Yi, “A Ten-Year Survey of Software Architecture,” IEEE International Conference on Software Engineering and Service Science (ICSESS), 2010
5. Microsoft, “Analyzing Requirements and Defining Microsoft .Net Solution Architectures,” MCSD Self-Paced Training Kit, Microsoft 2003.
6. Z. Li, “Internal individual Interviews with Architect in ABB CRC,” June, 2011.
7. M. Lopez, “Application of an evaluation framework for analyzing the architecture tradeoff analysis method,” The J. of System and Software Vol. 68, No. 3, Dec 2003.
8. K. Skadron, M. Martonosi, D. August “Challenges in Computer Architecture Evaluation,” Computer, 2003.
9. J. C. Duenas, W. L. de Oliveira, and J. A. de la Puente, “A Software Architecture Evaluation Model,” Proc. Second Int’l ESPRIT ARES Workshop, pp. 148-157, Feb. 1998.
10. L. G. Williams, C. U. Smith, “Performance Evaluation of Software Architectures.” Proc. of the 1st Int’l Workshop on Software and Performance.New York: ACM Press, 2002. 179-189
11. Van Gurp J., J. Bosch , “Automating software architecture assessment”, Proc. of the 9th Nordic Worship on Programming and Software Development Environment Research. Lillchammer, 2000.
12. J. Bosch and P. Molin, “Software Architecture Design: Evaluation and Transformation,” Proc. IEEE Eng. Of Computer Based Systems Symp., Dec. 1999
13. P. Clements, R. Kazman, M. Klein, “Evaluating Software Architectures, methods and case studies”, Addison-Wesley, 2002
14. R. Kazman, G. Abowd, L.Bass, and M.Webb, “Analyzing the Properties of User Interface Software Architectures,” Technical Report, CMU-CS-93-201, Carnegie Mellon Univ.,SchoolofComputerScience, 1993.
15. R. Kazman, G. Abowd, L. Bass, and P. Clements, “Scenario-Based Analysis of Software Architecture,” IEEE Software, Nov. 1996.
16. R. Kazman, G. Abowd, L.Bass, and M.Webb, “Analyzing the Properties of User Interface Software Architectures,” Technical Report, CMU-CS-93-201, Carnegie Mellon Univ.,SchoolofComputerScience, 1993.
17. R. Kazman, M. Klein, M. Barbacci, H. Lipson, T. Longstaff, and S.J. Carriere, “The Architecture Tradeoff Analysis method,” Proc. Fourth Int’l Conf. Eng. Of Complex Computer Systems (ICECCS’ 98), Aug. 1998.
18. N. Lassing, D. Rijsenbrij, and H. van Vliet, “On Software Architecture Analysis of Flexibility, Complexity of Changes: Size Isn’t Everything,” Proc. Second Nordic Software Architecture Workshop, 1999
19. G. Molter, “Integrating SAAM in Domain-Centric and Reuse-Based Development Processes,” Proc. Second Nordic Workshop Software Architecture (NOSA’ 99)
20. F. G. Olumofin and V. B. Misic, “Extending the ATAM Architecture Evaluation to Product Line Architectures”, Technical report TR 05/02 Department of computer science, university of Manitoba Winnipeg, Manitoba, Canada R3T 2N2, June 2005
21. P. Clements, SEI, CMU, http://www.sei.cmu.edu/architecture/tools/arid/ 2000
22. R. Kazman, J. Asundi, M. H. Klein, SEI, CMU, http://www.sei.cmu.edu/architecture/tools/cbam/ 2002
23. R.J. Pooley, and A.A.L. Abdullatif, “CPASA: Continuous Performance Assessment of Software Architectur,” Engineering of Computer-based Systems, IEEE International Conference on the Engineering of Computer-Based Systems, 2010.
24. A. Tang, F.-C Kuo and M.F. Lau “Towards Independent Software Architecture Review,” in 2nd European Conference on Software Architecture, 2008
25. J. Knodel, M. Lindvall, D. Muthig, M. Naab “Static evaluation of software architecture.” Proc. of the conf. on Software Maintenance and Reengineering (CSMR 2006).
26. A. Zalewski, “Beyond ATAM: Architecture Analysis in the Development of Large Scale Software Systems,” Lecture Notes in Computer Science, 2007.
27. T. Nakamura, V. R. Basili “Metrics of software architecture changes based on structural distance.” In Proc. of the 11th IEEE Int’l Software Metrics Symp.
28. L. M. Zhu, A. Aurum, “Tradeoff and sensitivity analysis in software architecture evaluation using analytic hierarchy process,” Software Quality Journal, 2005.
29. S. M.Yacoub and H. H. Ammar “A methodology for architecture-level reliability risk analysis.” IEEE Trans. On Software Engineering, 2002
30. S.J. Carriere, Lightweight Architecture Alternative Assessment Method, http://technogility.sjcarriere.com/2009/05/11/its-pronounced-like-lamb-not-like-lame.
31. E. Woods “Industrial Architectural Assessment using TARA.”, 2011 Ninth Working IEEE/IFIP Conference on Software Architecture, 2011
32. P. Bengtsson, P. N. Lassing, J. Bosch, and H. van Vliet “Architecture-Level Modifiability Analysis (ALMA)” Journal of System and Software, 2004.
33. P. Bengtsson and J. Bosch, “Architecture Level Prediction of Software Maintenance,” Proc. Third European conf. Software Maintenance and Reeng., 1999
34. C. Lung, S.Bot, K.Kalaichelvan, and R.Kazman, “An Approach to Software Architecture Analysis for Evolution and Reusability,” Proc. CASCON’97, Nov. 1997.
35. E. Folmer, J. van Gurp, and J. Bosch, “Software Architecture Analysis of Usability.” Proc EHCI-DSVIS2004, Springer LNCS Vol. 3425, 2005
36. IEEE 1061, “IEEE standard for a Software Quality Metrics”, IEEE, 1998
37. Karen Smiley and Jiang Zheng, “Writing strong functional and nonfunctional requirements”, ABB Internal training 2011