Distributed Training using TensorFlow Federated
May 25, 2022 Leave a comment
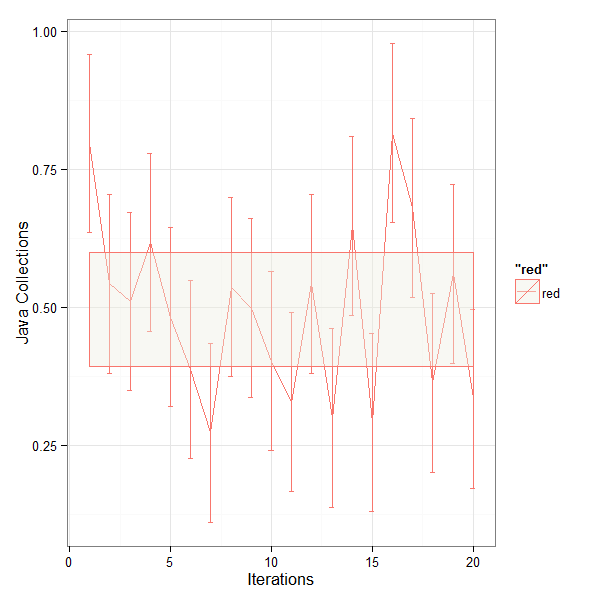
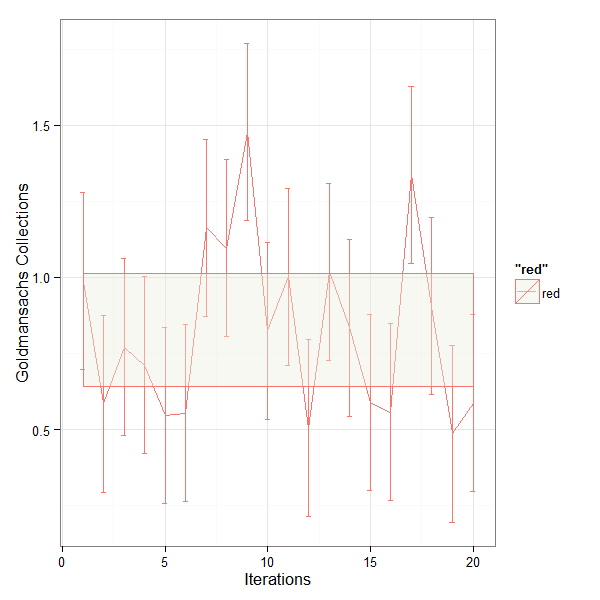
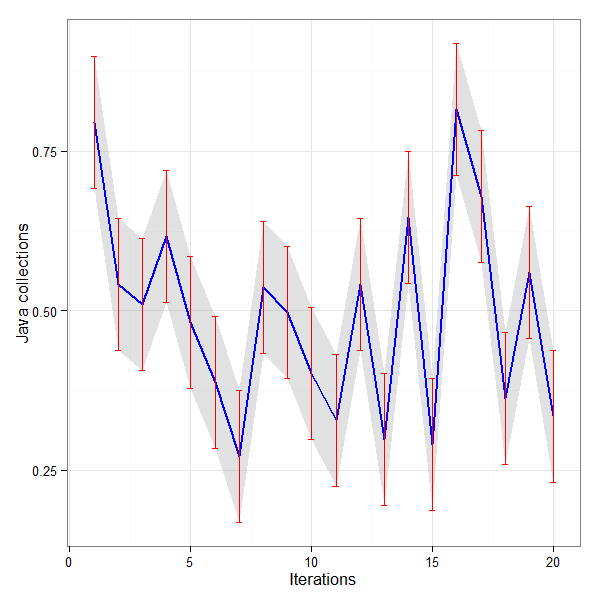
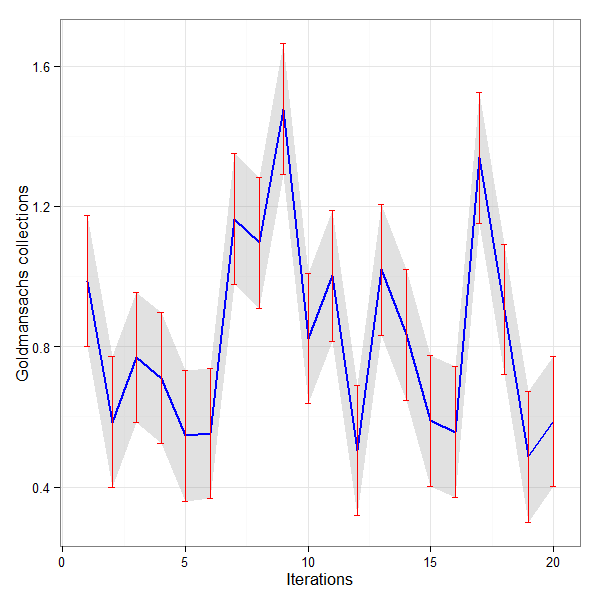
This is a very simple example of using multiple GPUs using a Jupyter Notebook to train a model. Obviously this involves multiple machines or VMs or in this case multiple processes in a simple Compute instance. Multiple processes in a single VM make it easier to test.
GPUs seem to be a costly affair.
I connected using SSH and these are the details of the VM
======================================
Welcome to the Google Deep Learning VM
======================================
Version: tf2-gpu.2-8.m92
Based on: Debian GNU/Linux 10 (buster) (GNU/Linux 4.19.0-20-cloud-amd64 x86_64\n)
Resources:
* Google Deep Learning Platform StackOverflow: https://stackoverflow.com/questions/tagged/google-dl-platform
* Google Cloud Documentation: https://cloud.google.com/deep-learning-vm
* Google Group: https://groups.google.com/forum/#!forum/google-dl-platform
To reinstall Nvidia driver (if needed) run:
sudo /opt/deeplearning/install-driver.sh
TensorFlow comes pre-installed with this image. To install TensorFlow binaries in a virtualenv (or conda env),
please use the binaries that are pre-built for this image. You can find the binaries at
/opt/deeplearning/binaries/tensorflow/
If you need to install a different version of Tensorflow manually, use the common Deep Learning image with the
right version of CUDA
Linux distributedtraining 4.19.0-20-cloud-amd64 #1 SMP Debian 4.19.235-1 (2022-03-17) x86_64
The programs included with the Debian GNU/Linux system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent
permitted by applicable law.
(base) root@distributedtraining:~# nvidia-smi
Wed May 25 04:59:48 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 64C P0 29W / 70W | 0MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 Tesla T4 Off | 00000000:00:05.0 Off | 0 |
| N/A 59C P0 30W / 70W | 0MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+Build Jupyter
Since my automatic build failed I built myself. Not sure why it should fail.
radhakrishnan_mohan@distributedtraining:~$ sudo -i
(base) root@distributedtraining:~# jupyter lab build --dev-build=False --minimize=False
[LabBuildApp] JupyterLab 3.2.9
[LabBuildApp] Building in /opt/conda/share/jupyter/lab
[LabBuildApp] Building jupyterlab assets (production, not minimized)
(base) root@distributedtraining:~# jupyter labextension list
JupyterLab v3.2.9
/opt/conda/share/jupyter/labextensions
nbdime-jupyterlab v2.1.1 enabled OK
jupyterlab-jupytext v1.3.8+dev enabled OK (python, jupytext)
jupyterlab_pygments v0.2.2 enabled OK (python, jupyterlab_pygments)
@jupyterlab/server-proxy v3.2.1 enabled OK
@jupyterlab/git v0.37.1 enabled OK (python, jupyterlab-git)
@jupyter-widgets/jupyterlab-manager v3.1.0 enabled OK (python, jupyterlab_widgets)
Other labextensions (built into JupyterLab)
app dir: /opt/conda/share/jupyter/lab
beatrix_jupyterlab v3.1.7 disabled OK
jupyterlab-plotly v5.8.0 enabled OK
plotlywidget v4.14.3 enabled OK
tensorflow_model_analysis v0.34.1 enabled OK
wit-widget v1.8.1 enabled OK
xai_tabular_widget v0.1.0 enabled OK
Assign GPU device to worker
It seems that it is imperative to assign a particular GPU to a worker as we have 2 Tesla P4 GPUs and 2 workers. If we don’t then there is failure to allocate GPU memory adequately. This line of code does that.
os.environ['CUDA_VISIBLE_DEVICES']=str(index)
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.


{kind=link}