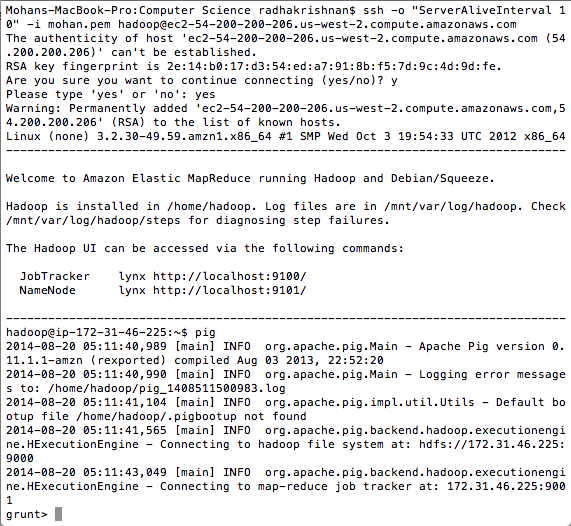
I was given this dataset( http://km.aifb.kit.edu/projects/btc-2010/). I believe it is RDF. But more importantly I executed some Pig Jobs locally and this is how it worked for me. The main idea here is how it helped me to learn about Pig MapReduce Jobs.
The data is in quads like this.
<http://openean.kaufkauf.net/id/businessentities/GLN_7654990000088> <http://www.w3.org/2000/01/rdf-schema#isDefinedBy> <http://openean.kaufkauf.net/id/businessentities/><http://openean.kaufkauf.net/id/businessentities/GLN_6406510000068> .
<http://openean.kaufkauf.net/id/businessentities/GLN_3521100000068> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://purl.org/goodrelations/v1#BusinessEntity> <http://openean.kaufkauf.net/id/businessentities/GLN_6406510000068> .
After processing by another Pig script I started working with this data.
(<http://openean.kaufkauf.net/id/businessentities/GLN_7612688000000>,3)
(<http://openean.kaufkauf.net/id/businessentities/GLN_7615990000096>,3)
(<http://openean.kaufkauf.net/id/businessentities/GLN_7634640000088>,3)
(<http://openean.kaufkauf.net/id/businessentities/GLN_7636150000008>,3)
(<http://openean.kaufkauf.net/id/businessentities/GLN_7636690000018>,3)
(<http://openean.kaufkauf.net/id/businessentities/GLN_7654990000088>,1)
(<http://openean.kaufkauf.net/id/businessentities/GLN_7657220000032>,3)
(<http://openean.kaufkauf.net/id/businessentities/GLN_7658940000098>,3)
(<http://openean.kaufkauf.net/id/businessentities/GLN_7659150000014>,3)
(<http://openean.kaufkauf.net/id/businessentities/GLN_7662880000018>,3)
The schema of the data is like this.
count_by_object: {group: chararray,count: long}
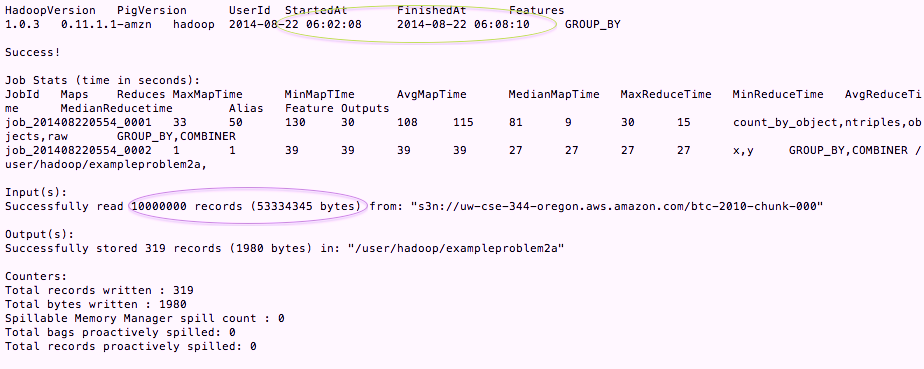
x = GROUP count_by_object BY count;
y = FOREACH x GENERATE group,COUNT(count_by_object);
Line 1 shown above groups the tuples by the count. This is what I get.
(1,{(<http://openean.kaufkauf.net/id/businessentities/GLN_7654990000088>,1)})
(3,{(<http://openean.kaufkauf.net/id/businessentities/GLN_0000049021028>,3),(<http://openean.kaufkauf.net/id/businessentities/GLN_0000054110120>,3),(<http://openean.kaufkauf.net/id/businessentities/GLN_0078477000014>,3),(<http://openean.kaufkauf.net/id/businessentities/GLN_0084610000032>,3),(<http://openean.kaufkauf.net/id/businessentities/GLN_0088720000050>,3),(<http://openean.kaufkauf.net/id/businessentities/GLN_0120490000028>,3),(<http://openean.kaufkauf.net/id/businessentities/GLN_0133770000090>,3),(<http://openean.kaufkauf.net/id/businessentities/GLN_0144360000086>,3),(<http://openean.kaufkauf.net/id/businessentities/GLN_0146140000040>,3),(<http://openean.kaufkauf.net/id/businessentities/GLN_0160080000038>,3),(<http://openean.kaufkauf.net/id/businessentities/GLN_0162990000030>,3),(<http://openean.kaufkauf.net/id/businessentities/GLN_0165590000028>,3),(<http://openean.kaufkauf.net/id/businessentities/GLN_0166620000056>,3),
.........
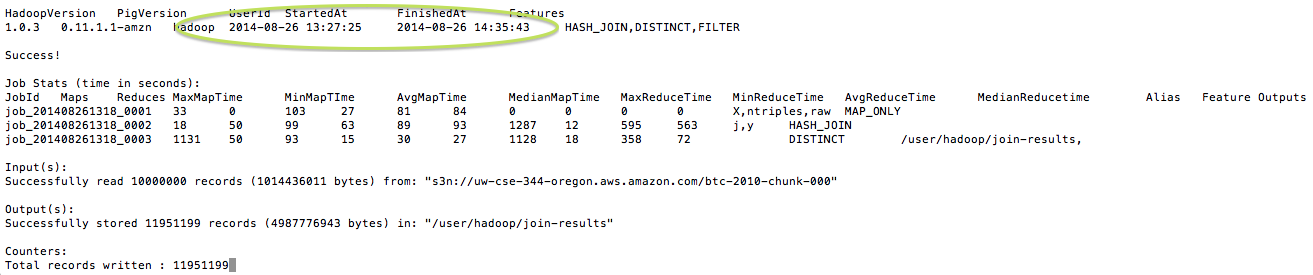
Line 2 of the Pig script give me this result.
(1,1)
(3,333)
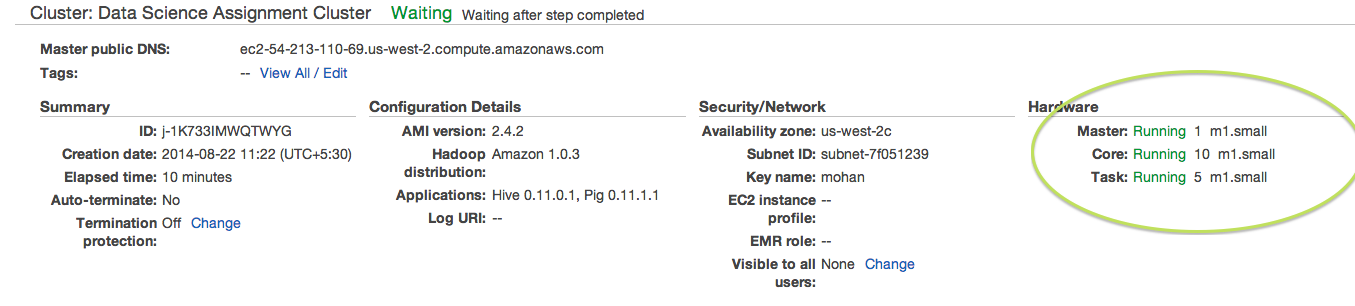
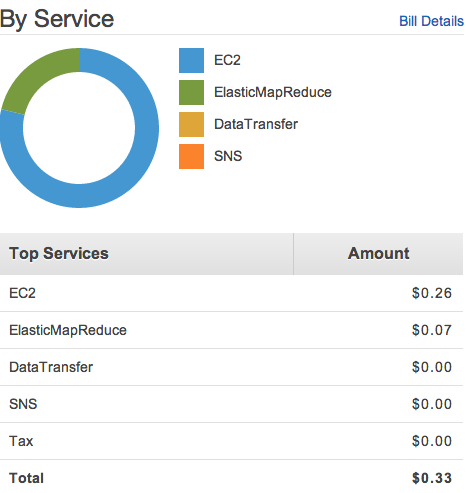
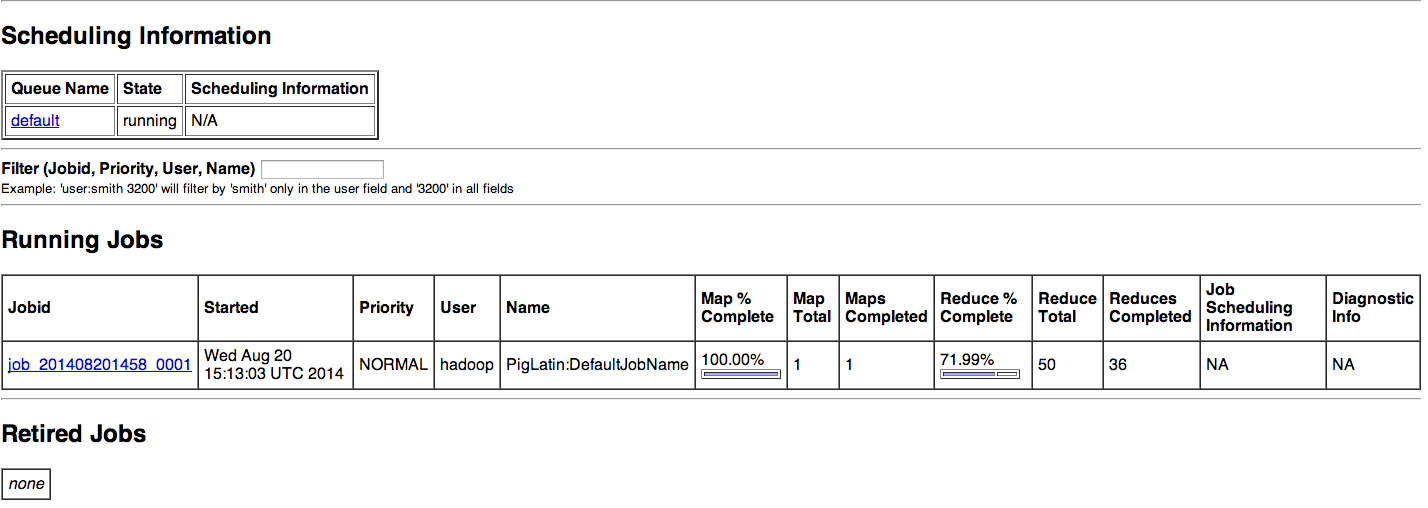
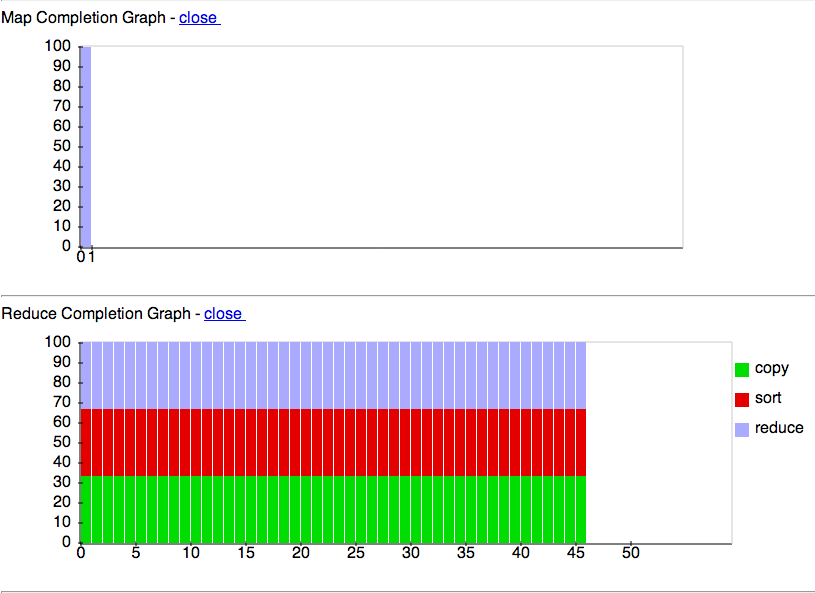
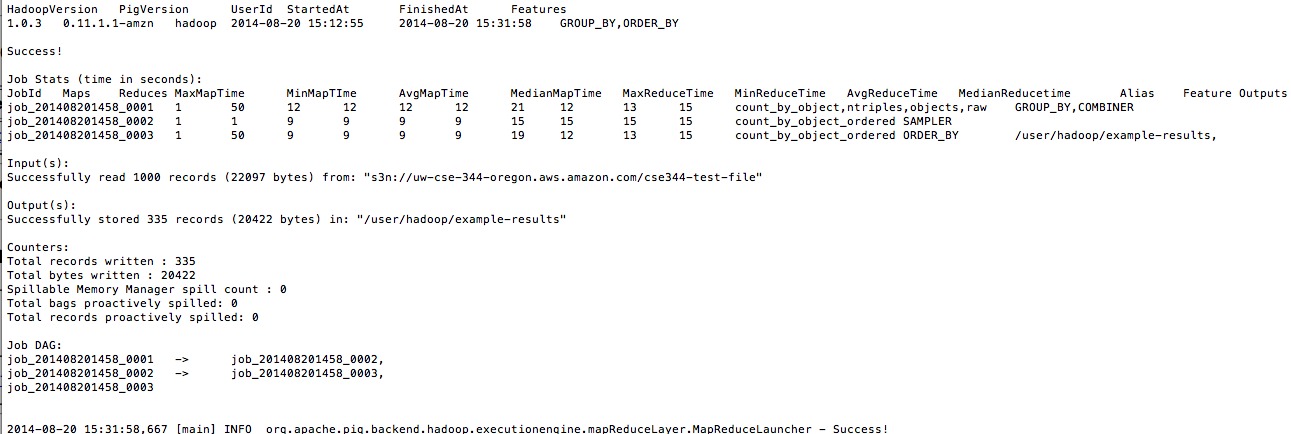
It is a interesting way to learn Pig which internally spawns Hadoop MapReduce Jobs. But the real fun is the Amazon Elastic MapReduce on-demand clusters. If the file is very large the EMR clusters should be used. It is basically Big Data analysis on the cloud.
 I recently pushed my AngularJS/Spring Boot/Rest application to Heroku.
I recently pushed my AngularJS/Spring Boot/Rest application to Heroku.