My AWS Pig Job
August 20, 2014 Leave a comment
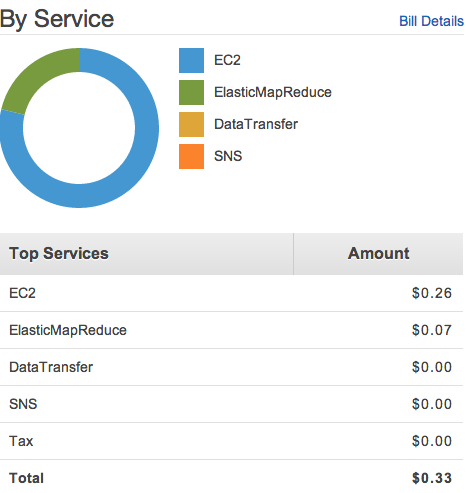
I executed some Pig Jobs on Elastic MapReduce by cloning the same cluster I used earlier(previous blog post). After that cluster setup my billing details were these.
I am still learning Pig. A sample of my pig commands are
grunt> fs -mkdir /user/hadoop grunt> fs -ls /user/hadoop grunt> register s3n://uw-cse-344-oregon.aws.amazon.com/myudfs.jar 2014-08-20 15:10:26,625 [main] INFO org.apache.pig.impl.io.FileLocalizer - Downloading file s3n://uw-cse-344-oregon.aws.amazon.com/myudfs.jar to path /tmp/pig8610216688759169361tmp/myudfs.jar 2014-08-20 15:10:26,632 [main] INFO org.apache.hadoop.fs.s3native.NativeS3FileSystem - Opening 's3n://uw-cse-344-oregon.aws.amazon.com/myudfs.jar' for reading 2014-08-20 15:10:26,693 [main] INFO org.apache.hadoop.util.NativeCodeLoader - Loaded the native-hadoop library grunt> raw = LOAD 's3n://uw-cse-344-oregon.aws.amazon.com/cse344-test-file' USING TextLoader as (line:chararray); grunt> ntriples = foreach raw generate FLATTEN(myudfs.RDFSplit3(line)) as (subject:chararray,predicate:chararray,object:chararray);
After submitting the jobs one can track the Jobs using the tracker UI.
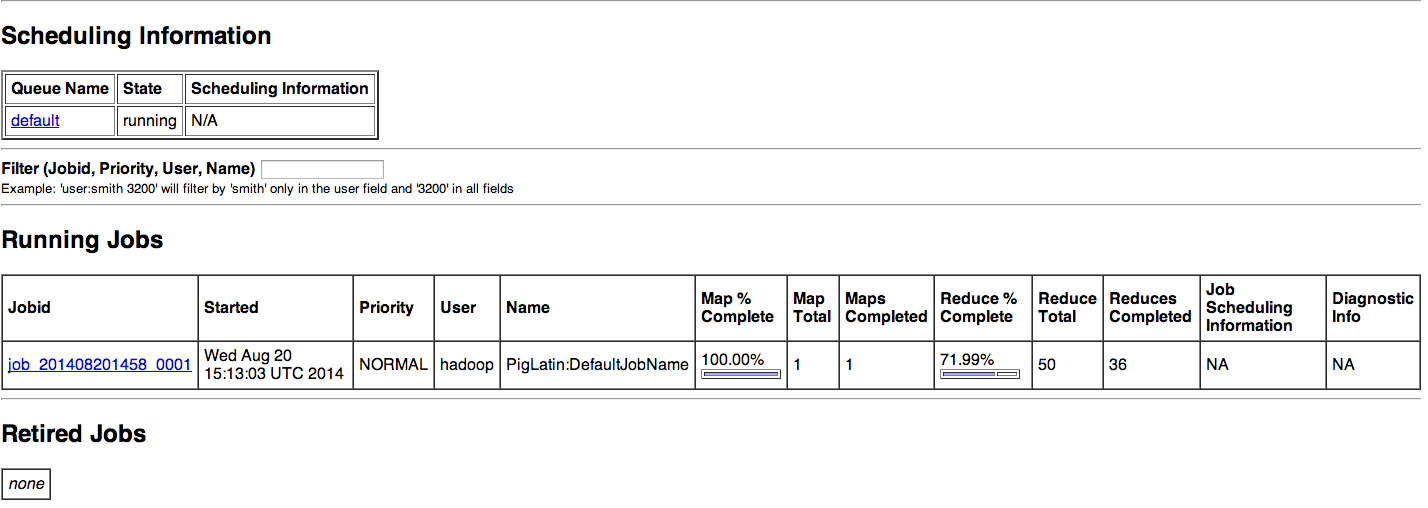
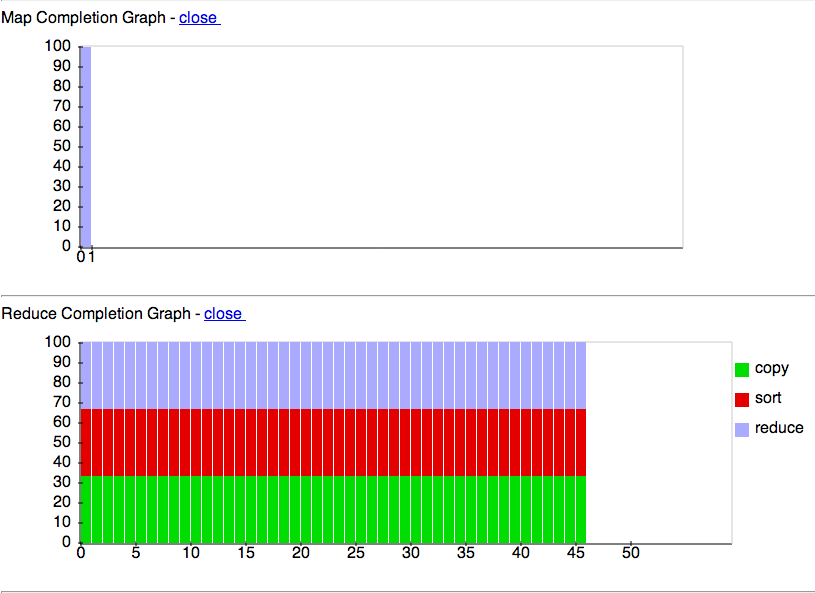
The successful completion of the Hadoop Jobs.
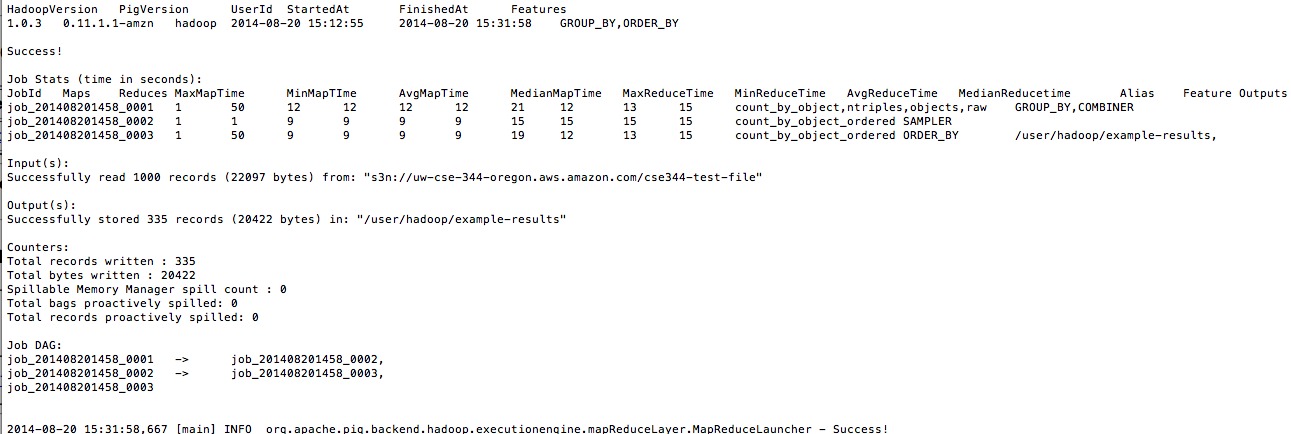
This is an emancipatory experience 🙂 One is set free from the local offshore job experience.
