One of our Jboss production servers runs out of Code cache based on the memory shortage reported when “CompilerThread1” is unable to proceed. I am not claiming at this time that I have understood this issue fully but I have attempted to track the utilization of the non-heap memory pool called ‘Code cache’ which is used to hold JIT compiled code.
The JMX API exposes this. I used Jboss’
to dump this at frequent intervals.
Total Memory Pools: 5Pool: Code Cache (Non-heap memory)Peak Usage : init:2359296, used:14647936, committed:14680064, max:50331648
Current Usage : init:2359296, used:14646848, committed:14680064, max:50331648
|-------------------| committed:14Mb
+---------------------------------------------------------------------+
|///////////////////| | max:48Mb
+---------------------------------------------------------------------+
|-------------------| used:13.97Mb
Pool: PS Eden Space (Heap memory)Peak Usage : init:89522176, used:229113856, committed:231866368, max:234684416
Current Usage : init:89522176, used:7292920, committed:229113856, max:232849408
|-------------------------------------------------------------------| committed:218.5Mb
+---------------------------------------------------------------------+
|// | | max:222.06Mb
+---------------------------------------------------------------------+
|-| used:6.96Mb
Pool: PS Survivor Space (Heap memory)Peak Usage : init:14876672, used:23715856, committed:34996224, max:34996224
Current Usage : init:14876672, used:0, committed:1441792, max:1441792
|---------------------------------------------------------------------| committed:1.38Mb
+---------------------------------------------------------------------+
| | max:1.38Mb
+---------------------------------------------------------------------+
| used:0b
Pool: PS Old Gen (Heap memory)Peak Usage : init:954466304, used:281887048, committed:954466304, max:1886519296
Current Usage : init:954466304, used:279802256, committed:954466304, max:1886519296
|----------------------------------| committed:910.25Mb
+---------------------------------------------------------------------+
|////////// | | max:1.76Gb
+---------------------------------------------------------------------+
|---------| used:266.84Mb
Pool: PS Perm Gen (Non-heap memory)Peak Usage : init:16777216, used:127850824, committed:214171648, max:1073741824
Current Usage : init:16777216, used:127821200, committed:128319488, max:1073741824
|-------| committed:122.38Mb
+---------------------------------------------------------------------+
|///////| | max:1Gb
+---------------------------------------------------------------------+
|-------| used:121.9Mb
Total Memory Pools: 5Pool: Code Cache (Non-heap memory)Peak Usage : init:2359296, used:14673408, committed:14712832, max:50331648
Current Usage : init:2359296, used:14672000, committed:14712832, max:50331648
|-------------------| committed:14.03Mb
+---------------------------------------------------------------------+
|///////////////////| | max:48Mb
+---------------------------------------------------------------------+
|-------------------| used:13.99Mb
Pool: PS Eden Space (Heap memory)Peak Usage : init:89522176, used:229113856, committed:231866368, max:234684416
Current Usage : init:89522176, used:47827272, committed:228982784, max:232718336
|-------------------------------------------------------------------| committed:218.38Mb
+---------------------------------------------------------------------+
|////////////// | | max:221.94Mb
+---------------------------------------------------------------------+
|-------------| used:45.61Mb
Pool: PS Survivor Space (Heap memory)Peak Usage : init:14876672, used:23715856, committed:34996224, max:34996224
Current Usage : init:14876672, used:0, committed:1572864, max:1572864
|---------------------------------------------------------------------| committed:1.5Mb
+---------------------------------------------------------------------+
| | max:1.5Mb
+---------------------------------------------------------------------+
| used:0b
Pool: PS Old Gen (Heap memory)Peak Usage : init:954466304, used:281887048, committed:954466304, max:1886519296
Current Usage : init:954466304, used:279509296, committed:954466304, max:1886519296
|----------------------------------| committed:910.25Mb
+---------------------------------------------------------------------+
|////////// | | max:1.76Gb
+---------------------------------------------------------------------+
|---------| used:266.56Mb
Pool: PS Perm Gen (Non-heap memory)Peak Usage : init:16777216, used:128416856, committed:214171648, max:1073741824
Current Usage : init:16777216, used:128416856, committed:128450560, max:1073741824
|-------| committed:122.5Mb
+---------------------------------------------------------------------+
|///////| | max:1Gb
+---------------------------------------------------------------------+
|-------| used:122.47Mb
Total Memory Pools: 5Pool: Code Cache (Non-heap memory)Peak Usage : init:2359296, used:14996864, committed:15106048, max:50331648
Current Usage : init:2359296, used:14995456, committed:15106048, max:50331648
|--------------------| committed:14.41Mb
+---------------------------------------------------------------------+
|////////////////////| | max:48Mb
+---------------------------------------------------------------------+
|-------------------| used:14.3Mb
Pool: PS Eden Space (Heap memory)Peak Usage : init:89522176, used:229113856, committed:231866368, max:234684416
Current Usage : init:89522176, used:23506784, committed:229113856, max:232194048
|--------------------------------------------------------------------| committed:218.5Mb
+---------------------------------------------------------------------+
|/////// || max:221.44Mb
+---------------------------------------------------------------------+
|------| used:22.42Mb
Pool: PS Survivor Space (Heap memory)Peak Usage : init:14876672, used:23715856, committed:34996224, max:34996224
Current Usage : init:14876672, used:0, committed:1769472, max:1769472
|---------------------------------------------------------------------| committed:1.69Mb
+---------------------------------------------------------------------+
| | max:1.69Mb
+---------------------------------------------------------------------+
| used:0b
Pool: PS Old Gen (Heap memory)Peak Usage : init:954466304, used:281951168, committed:954466304, max:1886519296
Current Usage : init:954466304, used:281951168, committed:954466304, max:1886519296
|----------------------------------| committed:910.25Mb
+---------------------------------------------------------------------+
|////////// | | max:1.76Gb
+---------------------------------------------------------------------+
|---------| used:268.89Mb
Pool: PS Perm Gen (Non-heap memory)Peak Usage : init:16777216, used:128552160, committed:214171648, max:1073741824
Current Usage : init:16777216, used:128552160, committed:128974848, max:1073741824
|-------| committed:123Mb
+---------------------------------------------------------------------+
|///////| | max:1Gb
+---------------------------------------------------------------------+
|-------| used:122.6Mb
I have used <code></code> above because the lines are too long. So we don’t see the HTML tags.
The relevant section is shown below. I am interested in the non-heap memory pool called Code Cache
which holds the JIT compiled code.
<b>Total Memory Pools:</b> 5<blockquote><b>Pool: Code Cache</b> (Non-heap memory)
<blockquote>Peak Usage : init:2359296, used:14647936, committed:14680064, max:50331648<br>
Current Usage : init:2359296, used:14646848, committed:14680064, max:50331648<blockquote>
First part of the code
library(XML)
library(stringr)
this.dir <- dirname(parent.frame(2)$ofile)
setwd(this.dir)
tables <- htmlParse("D:\\Log Analysis\\MaxBank\\Oct 24\\memorypools")
y <- xpathSApply(tables,"//b//text()[contains(.,'Pool: Code Cache')]//following::blockquote[1]",xmlValue)
y <- data.frame(y)
y <- apply( y, 1, function(z) str_extract(z,"Current.*?[/|]"))
data <- str_extract_all(y,"[0-9]+(/,|/|)")
data <- data.frame(matrix(unlist(data),ncol=4,byrow=T))
colnames(data) <- c("Init", "Used", "Committed", "Max")
data["Time"] <- "NA"
data$Time <- seq(200, nrow(data)*200, by=200)
data$Used <- as.numeric(levels(data$Used)[data$Used])/(1024*1024)
data$Committed <- as.numeric(levels(data$Committed)[data$Committed])/(1024*1024)
data$Max<- as.numeric(levels(data$Max)[data$Max])/(1024*1024)
The most difficult part was the XPath in this line. ‘R’ has support for XPath. I use a combination of
XPath and Regex to get the current usage data and convert it to MB.
Since I know that the data was collected at an interval of 200 seconds I have added a column to the data frame with this data. The collected data does not have a timestamp.
y <- xpathSApply(tables,"//b//text()[contains(.,'Pool: Code Cache')]//following::blockquote[1]",xmlValue)
Second part of the code
png(
"code-cache.png",
width =1200, height = 490)
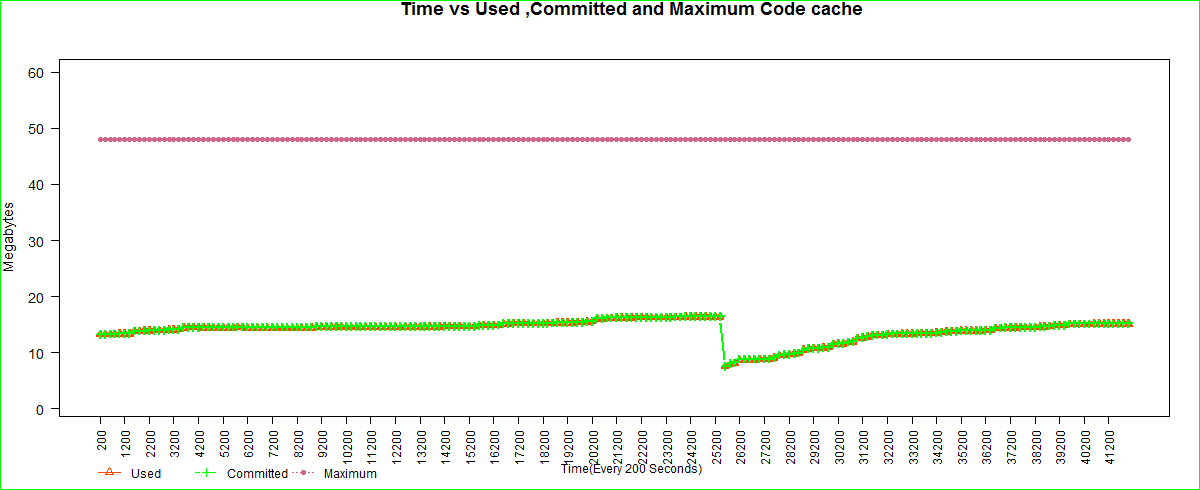
plot(data$Time,as.numeric(data$Used),ylim=c(1,60),col="orangered",pch=2,type="b", ylab="Megabytes", xlab="",las=2,lwd=2,xaxt="n", cex.lab=1.2,cex.axis=1.2)
axis(1,at = seq(min(data$Time), max(data$Time), by=1000),las = 2,cex.axis=1)
par(mar=c(5,5.5,1,1))
par(oma=c(0,0,0,0) )
box("figure",lty="solid", col="green")
title("Time vs Used ,Committed and Maximum Code cache",cex.main=1.5,xlab="Time(Every 200 Seconds)")
points(data$Time,as.numeric(data$Committed),col="green",pch=3,lwd=2, cex.lab=1.2,cex.axis=1,type="b")
points(data$Time,as.numeric(data$Max),col="palevioletred3",pch=16,lwd=2, cex.lab=1.2,cex.axis=1,type="b")
par(xpd=TRUE)
legend(3.8,-9,c("Used", "Committed", "Maximum"), pch = c(2,3,16), lty = c(1,2,3),col=c('orangered','green','palevioletred3'),ncol=3,bty ="n")
dev.off()
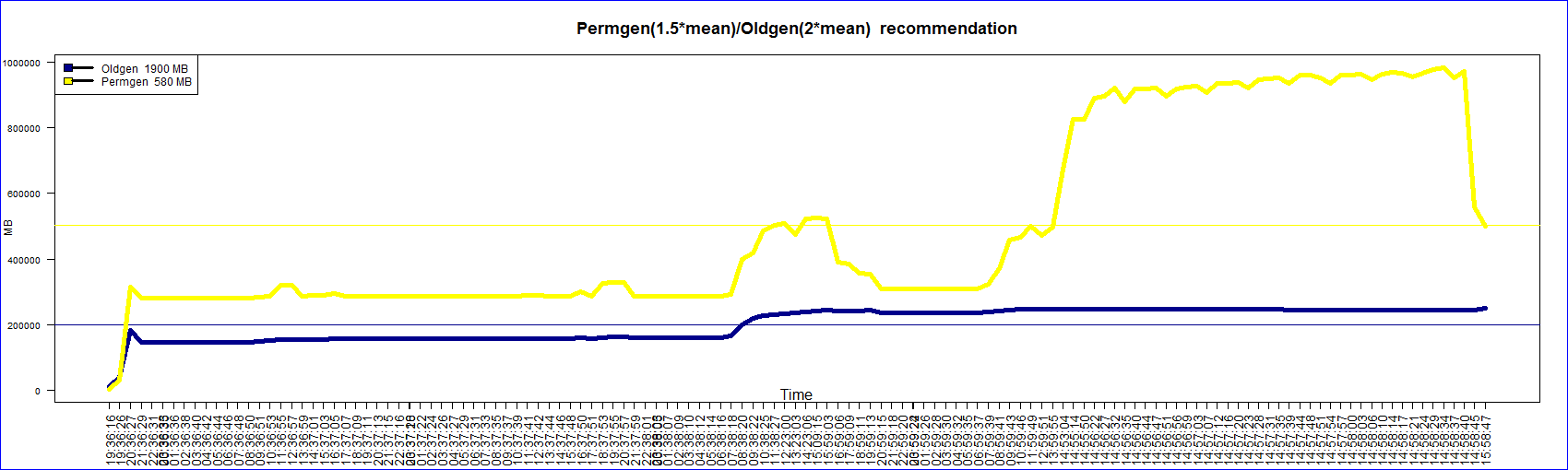
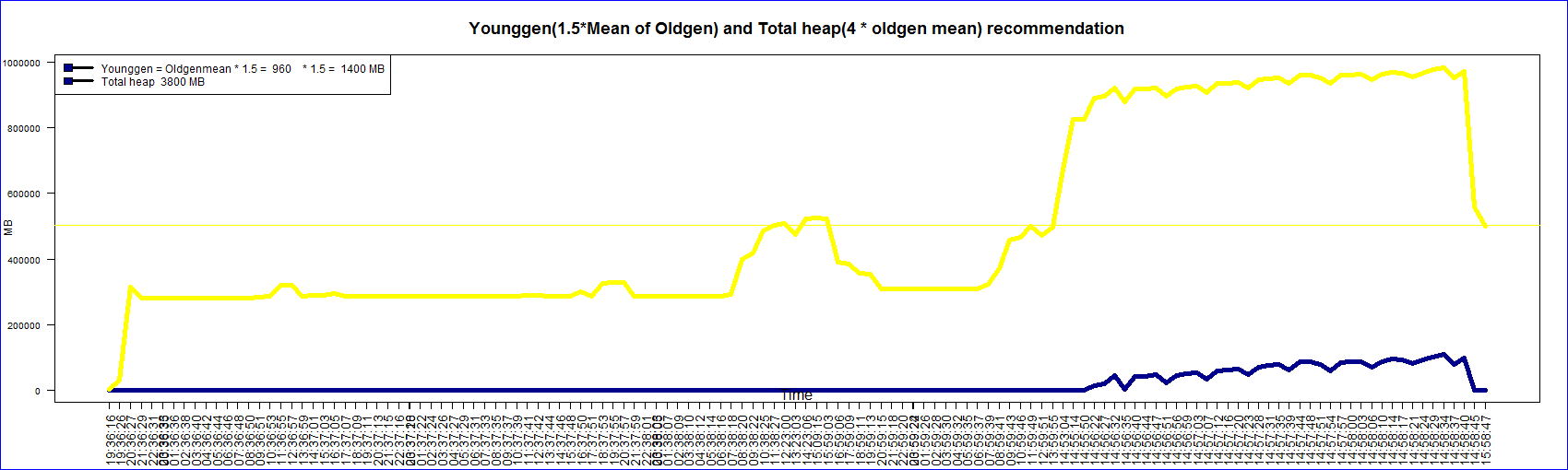
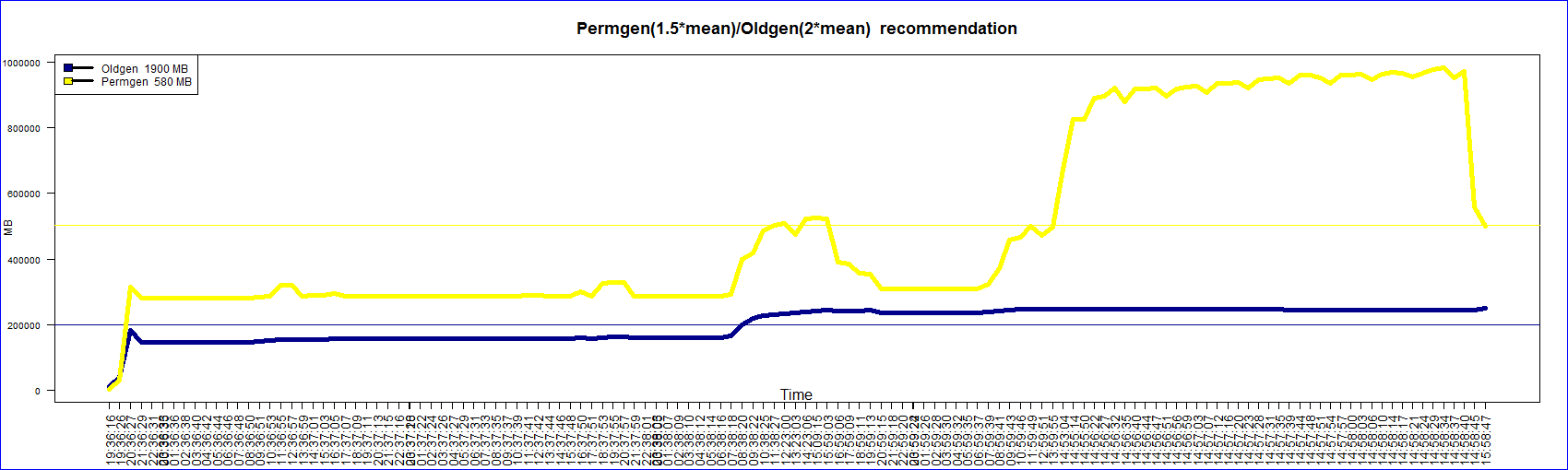
The Committed and Used graph lines are together because the data is almost the same. There are some lines of ‘R’ code that are from the forums. In fact some lines related to graph layout may not be required. I always find it difficult to layout the graph. In this case the legend is at the bottom and finding space for it was hard.
When I started exploring this aspect of the JVM memory pool I was not aware that one could dump the current memory pool utilization data like this.
Kirk Pepperdine(jClarity) pointed out that he has a VisualVM plugin(https://java.net/projects/memorypoolview/) to look at JVM memory pools.