I have used R Data Frames and they were very versatile and compared to that the pandas Data Frames seem slightly harder to get right. But I am after the excellent support for Machine Learning and data analytics that scikit provides.
I have used R Data Frames and they were very versatile and compared to that the pandas Data Frames seem slightly harder to get right. But I am after the excellent support for Machine Learning and data analytics that scikit provides.
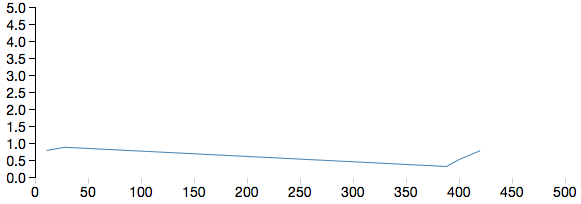
This graph is simple and I usually parse Java GC logs to practise. I plan to parse the Java G1 GC log to get my hands dirty by using pandas Data Frames.
AfterSize BeforeSize RealTime SecondsSinceLaunch TotalSize
0 20 3.109 9216 2014-05-13T13:24:35.091 5029
1 9125 3.459 9216 2014-05-13T13:24:35.440 6077
2 25 5.599 9216 2014-05-13T13:24:37.581 8470
3 44 10.704 9216 2014-05-13T13:24:42.686 15
4 51 16.958 9216 2014-05-13T13:24:48.941 20
5 92 24.066 9216 2014-05-13T13:24:56.049 26
6 602 62.383 9216 2014-05-13T13:25:34.368 68
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
def main():
gclog = pd.DataFrame(columns=['SecondsSinceLaunch',
'BeforeSize',
'AfterSize',
'TotalSize',
'RealTime'])
with open("D:\\performance\\data.txt", "r") as f:
for line in f:
strippeddata = line.split()
gclog = gclog.append(pd.DataFrame( [dict(SecondsSinceLaunch=strippeddata[0],
BeforeSize=strippeddata[1],
AfterSize=strippeddata[2],
TotalSize=strippeddata[3],
RealTime=strippeddata[4])] ),
ignore_index=True)
print gclog
#gclog.time = pd.to_datetime(gclog['SecondsSinceLaunch'], format='%Y-%m-%dT%H:%M:%S.%f')
gclog = gclog.convert_objects(convert_numeric=True)
plt.plot(gclog.TotalSize, gclog.AfterSize)
plt.show()
if __name__=="__main__":
main()

Update :
The graph shown above is not clear and it looks wrong. I have improved it to some extent using this code. Matplotlib has many features more powerful than what I used earlier. I have commented the code used to annotate and display the actual points in the graph. I couldn’t properly draw the tick marks so that the red graph is clearly shown because the data range wasn’t easy to work with. There should be some feature that I still have not explored.
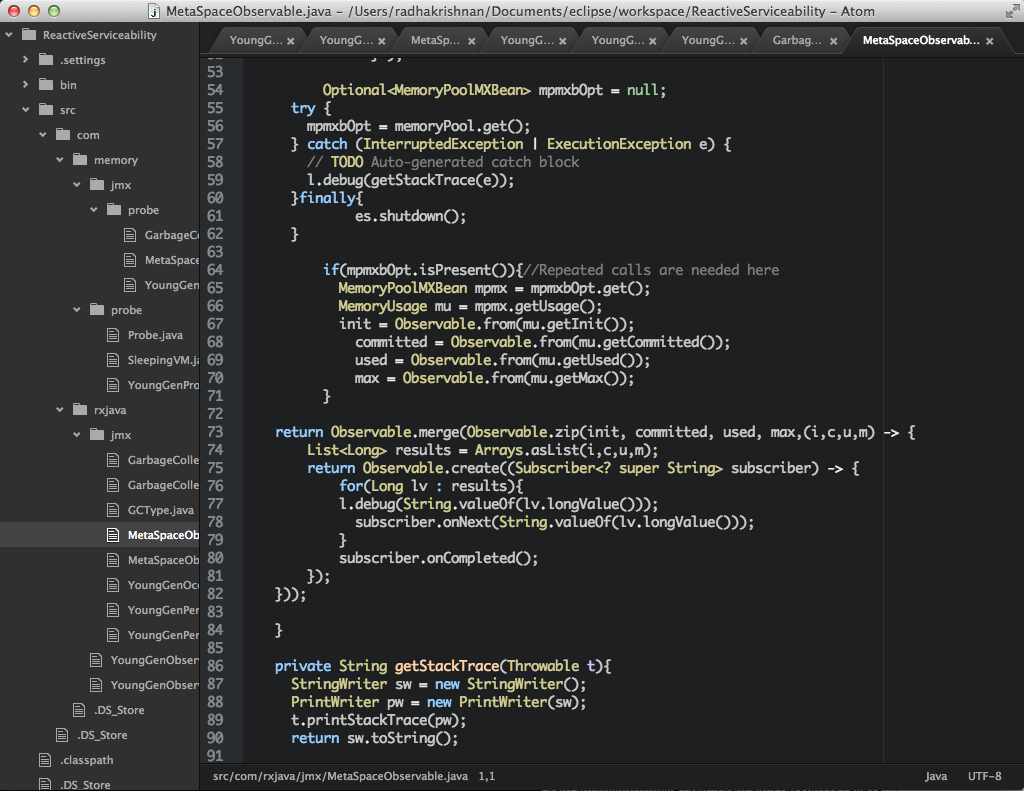
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import numpy as np
def main():
gclog = pd.DataFrame(columns=['SecondsSinceLaunch',
'BeforeSize',
'AfterSize',
'TotalSize',
'RealTime'])
with open("D:\\performance\\data.txt", "r") as f:
for line in f:
strippeddata = line.split()
gclog = gclog.append(pd.DataFrame( [dict(SecondsSinceLaunch=strippeddata[0],
BeforeSize=strippeddata[1],
AfterSize=strippeddata[2],
TotalSize=strippeddata[3],
RealTime=strippeddata[4])] ),
ignore_index=True)
print gclog
#gclog.time = pd.to_datetime(gclog['SecondsSinceLaunch'], format='%Y-%m-%dT%H:%M:%S.%f')
gclog = gclog.convert_objects(convert_numeric=True)
fig, ax = plt.subplots(figsize=(17, 14), facecolor='white', edgecolor='white')
ax.axes.tick_params(labelcolor='darkblue', labelsize='10')
for axis, ticks in [(ax.get_xaxis(), np.arange(10, 8470, 100) ), (ax.get_yaxis(), np.arange(10, 9125, 300))]:
axis.set_ticks_position('none')
axis.set_ticks(ticks)
axis.label.set_color('#999999')
if False: axis.set_ticklabels([])
plt.grid(color='#999999', linewidth=1.0, linestyle='-')
plt.xticks(rotation=70)
plt.gcf().subplots_adjust(bottom=0.15)
map(lambda position: ax.spines[position].set_visible(False), ['bottom', 'top', 'left', 'right'])
ax.set_xlabel(r'AfterSize'), ax.set_ylabel(r'TotalSize')
ax.set_xlim(10, 8470, 100), ax.set_ylim(10, 9125, 300)
plt.plot(sorted(gclog.AfterSize),gclog.TotalSize,c="red")
# for i,j in zip(sorted(gclog.AfterSize),gclog.TotalSize):
# ax.annotate('(' + str(i) + ',' + str(j) + ')',xy=(i, j))
plt.show()
if __name__=="__main__":
main()