PlantUML
June 5, 2015 1 Comment
There was a time when I was studiously reading UML 2 articles like this one about the UML 2 Composition Model.
This also reminds me of The Journal of Object Technology.
Its mission statement is this.
The Journal of Object Technology (JOT) is a peer-reviewed, free and open-access journal dedicated to the timely publication of previously unpublished research articles, surveys, tutorials, and technical notes on all aspects of object technology.
But I have never been able to draw the kind of UML 2 diagrams that Conrad Bock describes in his articles in the JOT. Visual Paradigm for UML is the tool that I think is the most flexible and I have used both the Community Edition as well as the licensed version. StarUML is good too but not as versatile as Visual Paradigm.
Later on I started using TikZ and PGF and Graphviz and liked them very much.
UML was passe but I still use it.
Recently I started using PlantUML for a code review project and it was like a whiff of fresh air. It uses Graphviz and there are IDE plugins. Everything was easy to learn and use. I could open IntelliJ IDEA and browse the code and also type the PlantUML Domain-specific language code and draw a complex UML 2 diagram.
It is easy for the developers to design their code.I wish they paid heed to someone.
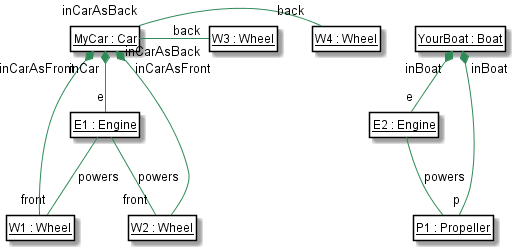
@startuml
skinparam class {
BackgroundColor WHite
ArrowColor SeaGreen
BorderColor Black
}
class "<u>MyCar : Car"{
+myMethods()
}
class "<u>YourBoat : Boat"{
+myMethods()
}
class "<u>E2 : Engine"{
String name
}
class "<u>P1 : Propeller"{
String name
}
class "<u>E1 : Engine"{
String name
}
class "<u>W1 : Wheel"{
String name
}
class "<u>W2 : Wheel"{
String name
}
class "<u>W3 : Wheel"{
String name
}
class "<u>W4 : Wheel"{
String name
}
"<u>E1 : Engine" -- "front" "<u>W1 : Wheel" : "powers"
"<u>E1 : Engine" -- "front" "<u>W2 : Wheel" : "powers"
"<u>E2 : Engine" -- "<u>P1 : Propeller" : "powers"
"<u>YourBoat : Boat" "inBoat" *-- "p" "<u>P1 : Propeller"
"<u>YourBoat : Boat" "inBoat" *-- "e" "<u>E2 : Engine"
"<u>MyCar : Car" "inCarAsBack" *-- "<u>W1 : Wheel"
"<u>MyCar : Car" "inCarAsBack" *-- "<u>W2 : Wheel"
"<u>MyCar : Car" "inCarAsBack" -right--- "back" "<u>W3 : Wheel"
"<u>MyCar : Car" "inCarAsBack" -right--- "back" "<u>W4 : Wheel"
"<u>MyCar : Car" "inCar" *-- "e" "<u>E1 : Engine"
hide members
hide circle
@enduml
Update 1:
The flow final activity is in the UML 2 spec. If it is not desired to abort all flows in the activity, use flow final instead. It is a circle with a cross inside. But I didn’t see that in the PlantUML doc.
How can I create it ?
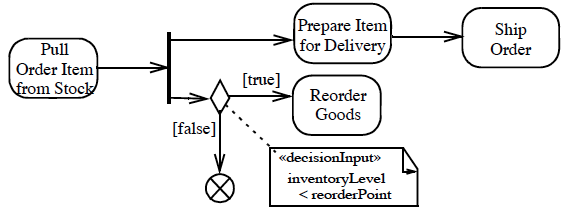
The PlantUML team responded.
Well, it’s not possible today.
However, we propose that we have now 2 keywords :
stop (that will display the actual circle)
end (that will display a circle with a cross inside)
Update 2:
What’s New ?
7 June, 2015: Add end keyword in Activity Diagram Beta. (Thanks to Radhakrishnan Mohan for the suggestion).
Is this ok for you, or do you prefer to stay anonymous ?
PS : You can test the beta version here https://dl.dropboxusercontent.com/u/13064071/plantuml.jar



