Videos and articles to view and read
December 6, 2013 Leave a comment
Ask Forgiveness. Not permission.
December 6, 2013 Leave a comment
This will be very useful for people like me who want to apply this to Capacity Planning
Rob Tibshirani and I are offering a MOOC in January on Statistical Learning.
This “massive open online course" is free, and is based entirely on our new book
“An Introduction to Statistical Learning with Applications in R”
(James, Witten, Hastie, Tibshirani 2013, Springer). http://www-bcf.usc.edu/~gareth/ISL/
The pdf of the book will also be free.
The course, hosted on Open edX, consists of video lecture segments, quizzes, video R sessions, interviews with famous statisticians,
lecture notes, and more. The course starts on January 22 and runs for 10 weeks.
Please consult the course webpage http://statlearning.class.stanford.edu/ to enroll and for for further details.
----------------------------------------------------------------------------------------
Trevor Hastie hastie@stanford.edu
Professor, Department of Statistics, Stanford University
Phone: (650) 725-2231 Fax: (650) 725-8977
URL: http://www.stanford.edu/~hastie
address: room 104, Department of Statistics, Sequoia Hall
390 Serra Mall, Stanford University, CA 94305-4065
--------------------------------------------------------------------------------------
December 4, 2013 Leave a comment
This code solved one of the problems. It accumulates all the matches by looping over m.find(). The main problem is still not solved. It does not work on the result of the previous match.
So the result is wrong.
[Current Usage : init:2359296, used:13913536, committed:13959168, max:50331648|]
[Current Usage : init:2359296, used:13915200, committed:13959168, max:50331648|]
[2359296, 13914944, 13959168, 50331648, 2359296, 13913536, 13959168, 50331648, 13, 31, 48, 13, 27]
[2359296, 13916608, 13959168, 50331648, 2359296, 13915200, 13959168, 50331648, 13, 31, 48, 13, 27]
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.function.Function;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class SimplerFlatMapTest {
public static void main( String... argv ){
List<String> source = new ArrayList<String>();
source.add( "Peak Usage : init:2359296, used:13914944, committed:13959168, max:50331648Current Usage : init:2359296, used:13913536, committed:13959168, max:50331648|------------------| committed:13.31Mb+---------------------------------------------------------------------+|//////////////////| | max:48Mb+---------------------------------------------------------------------+|------------------| used:13.27Mb");
source.add( "Peak Usage : init:2359296, used:13916608, committed:13959168, max:50331648Current Usage : init:2359296, used:13915200, committed:13959168, max:50331648|------------------| committed:13.31Mb+---------------------------------------------------------------------+|//////////////////| | max:48Mb+---------------------------------------------------------------------+|------------------| used:13.27Mb");
List<Pattern> patterns = Arrays.asList(Pattern.compile("Current.*?[/|]"), Pattern.compile("[0-9]+(/,|/|)"));
Function<Matcher, List<String>> matches1 = m -> {
List<String> list = new ArrayList<String>();
while(m.find()) {
list.add(m.group());
}
return list;
};
patterns.stream()
.flatMap(p -> source.stream().map(p::matcher))
.map(matches1)
.forEach(System.out::println);
}
}
December 3, 2013 Leave a comment
I compiled this code with
java version "1.8.0-ea"
Java(TM) SE Runtime Environment (build 1.8.0-ea-b113)
Java HotSpot(TM) 64-Bit Server VM (build 25.0-b55, mixed mode)
The documentation of flatMap was not easy to understand but there are two streams that are mixed – the source stream and the regular expression pattern stream. I am applying the regular expressions one by one on the source lines to get what I want. So here I am able to get the first value(2359296) from the line
The problem with this approach is this. The result of the first regex match is this line.
Current Usage : init:2359296, used:13913536, committed:13959168, max:50331648|
The second regex should be applied on this line. Not on the original line. But that is how this code works. Moreover it does not give me all the values returned by looping over Matcher::find
Not the other values. I have to find a way of coding it to get all.
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.function.Function;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class FlatMapTest {
public static void main( String... argv ){
List<String> source = new ArrayList<String>();
source.add( "Peak Usage : init:2359296, used:13914944, committed:13959168, max:50331648Current Usage : init:2359296, used:13913536, committed:13959168, max:50331648|------------------| committed:13.31Mb+---------------------------------------------------------------------+|//////////////////| | max:48Mb+---------------------------------------------------------------------+|------------------| used:13.27Mb");
source.add( "Peak Usage : init:2359296, used:13916608, committed:13959168, max:50331648Current Usage : init:2359296, used:13915200, committed:13959168, max:50331648|------------------| committed:13.31Mb+---------------------------------------------------------------------+|//////////////////| | max:48Mb+---------------------------------------------------------------------+|------------------| used:13.27Mb");
List<Pattern> patterns = Arrays.asList(Pattern.compile("Current.*?[/|]"), Pattern.compile("[0-9]+(/,|/|)"));
//Style 1
patterns.stream()
.flatMap(new Function<Pattern, Stream<String>>() {
@Override
public Stream<String> apply(Pattern p) {
return source.stream()
.map(p::matcher)
.filter(Matcher::find)
.map(Matcher::group);
}
})
.forEach(System.out::println);
//Style 2
patterns.stream().flatMap(( Pattern p1 ) -> source.
stream().
map(p1::matcher).
filter(Matcher::find).map(matcher -> matcher.group())).forEach(x -> System.out.println(x));
}
}
December 2, 2013 Leave a comment
> head(y)
y 1 Peak Usage : init:2359296, used:13914944, committed:13959168, max:50331648Current Usage : init:2359296, used:13913536, committed:13959168, max:50331648|------------------| committed:13.31Mb+---------------------------------------------------------------------+|//////////////////| | max:48Mb+---------------------------------------------------------------------+|------------------| used:13.27Mb
> y <- apply( y, 1, function(z) str_extract(z,"Current.*?[/|]"))
[1] "Current Usage : init:2359296, used:13913536, committed:13959168, max:50331648|"
The ‘R’ function ‘apply’ can operate on a data structure and apply a regular expression. It gives back a data structure with the new values.
I think the equivalent Java Lambda code could be like this. It may not be optimal but the result is similar.
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import java.util.stream.Collectors;
public class ArrayListStream {
public static void main( String... argv ){
List<String> list = new ArrayList();
list.add( "Peak Usage : init:2359296, used:13914944, committed:13959168, max:50331648Current Usage : init:2359296, used:13913536, committed:13959168, max:50331648|------------------| committed:13.31Mb+---------------------------------------------------------------------+|//////////////////| | max:48Mb+---------------------------------------------------------------------+|------------------| used:13.27Mb");
list.add( "Peak Usage : init:2359296, used:13916608, committed:13959168, max:50331648Current Usage : init:2359296, used:13915200, committed:13959168, max:50331648|------------------| committed:13.31Mb+---------------------------------------------------------------------+|//////////////////| | max:48Mb+---------------------------------------------------------------------+|------------------| used:13.27Mb");
Pattern p = Pattern.compile( "Current.*?[/|]" );
List list1 = list.
stream().
map(p::matcher).
filter(Matcher::find).map(matcher -> matcher.group()).
collect(Collectors.toCollection(ArrayList::new));
System.out.println(list1.get(0));
}
}
November 29, 2013 Leave a comment
I think Java lambdas have some powerful functional programming support and this is an attempt to convert part of the ‘R’ code to Java.
I start with this line from the GC log file.
Total Memory Pools: 5
Pool: Code Cache (Non-heap memory)
Peak Usage : init:2359296, used:13914944, committed:13959168, max:50331648
Current Usage : init:2359296, used:13913536, committed:13959168, max:50331648|------------------| committed:13.31Mb
+---------------------------------------------------------------------+
|//////////////////| | max:48Mb
+---------------------------------------------------------------------+
|------------------| used:13.27MbPool: PS Eden Space (Heap memory)
Peak Usage : init:89522176, used:186449920, committed:234356736, max:234618880
Current Usage : init:89522176, used:36258088, committed:233570304, max:233635840|--------------------------------------------------------------------| committed:222.75Mb
+---------------------------------------------------------------------+
|////////// || max:222.81Mb
+---------------------------------------------------------------------+
|---------| used:34.58MbPool: PS Survivor Space (Heap memory)
Peak Usage : init:14876672, used:25217592, committed:35651584, max:35651584
Current Usage : init:14876672, used:0, committed:1114112, max:1114112|---------------------------------------------------------------------| committed:1.06Mb
+---------------------------------------------------------------------+
| | max:1.06Mb
+---------------------------------------------------------------------+
| used:0bPool: PS Old Gen (Heap memory)
Peak Usage : init:954466304, used:272270080, committed:954466304, max:1886519296
Current Usage : init:954466304, used:269639088, committed:954466304, max:1886519296|----------------------------------| committed:910.25Mb
+---------------------------------------------------------------------+
|////////// | | max:1.76Gb
+---------------------------------------------------------------------+
|---------| used:257.15MbPool: PS Perm Gen (Non-heap memory)
Peak Usage : init:16777216, used:112329944, committed:210763776, max:1073741824
Current Usage : init:16777216, used:112329944, committed:112852992, max:1073741824|------| committed:107.62Mb
+---------------------------------------------------------------------+
|//////| | max:1Gb
+---------------------------------------------------------------------+
|------| used:107.13Mb
tables <- htmlParse("memorypools.txt")
y <- xpathSApply(tables,"//b//text()[contains(.,'Pool: Code Cache')]//following::blockquote[1]",xmlValue)
y <- data.frame(y)
I use ‘R’ to parse the line first because I found it hard to use Java to parse the unstructured line with HTML tags
After the first phase the line looks like this.
[1] "Peak Usage : init:2359296, used:13914944, committed:13959168, max:50331648Current Usage : init:2359296, used:13913536, committed:13959168, max:50331648|------------------| committed:13.31Mb+---------------------------------------------------------------------+|//////////////////| | max:48Mb+---------------------------------------------------------------------+|------------------| used:13.27Mb"
import java.io.IOException;
import java.nio.file.Files;
import java.util.Scanner;
import java.util.stream.Stream;
import static java.nio.charset.StandardCharsets.UTF_8;
import static java.nio.file.Paths.get;
public class GCLogParser {
private void readFile() throws IOException {
Stream<String> s = Files.lines(get("gclog.txt"), UTF_8);
s.forEach( this::parse );
}
public static void parseDocument(Parseable parser,
String data){
parser.apply(data);
}
private void parse( String data ){
Scanner s = new Scanner( data );
s.findInLine("Current.*?[/|]");
System.out.println(s.match().group());
}
public static void main( String... argv ) throws IOException {
new GCLogParser().readFile();
}
@FunctionalInterface
public interface Parseable{
void apply( String s);
}
}
This Java code gives me this line. This is just new syntax and constrcts and I don’t think I have used the functional style of programming properly here.
Current Usage : init:2359296, used:15775680, committed:15859712, max:50331648|
November 22, 2013 Leave a comment
The Java magazine carries an article on Performance tuning.
When I read this line I stopped and posted it here. This is exactly what is happening in our production systems. Aha !
The bottleneck is almost certainly where you think it is.
Trust in your amazing analytical skills—they will lead you to the right culprit, which is usually any code that wasn’t written by you.
November 14, 2013 Leave a comment
I have chosen some values from these guidelines from Charlie Hunt’s book. This is the latest ‘R’ code. That last blog entry has the old code.
I am using some of these general rules just as a foundation for further calculation. Generally our capacity planning teams do not have any baseline. I have not investigated the actual justification for some of these figures.
Guidelines for Calculating Java Heap Sizing
Java heap - 3x to 4x old generation space occupancy
after full garbage collection
Permanent Generation - 1.2x to 1.5x permanent generation space
occupancy after full garbage collection
Young Generation - 1x to 1.5x old generation space
occupancy after full garbage collection
Old Generation Implied from overall Java heap size minus the young
generation size
2x to 3x old generation space occupancy
after full garbage collection
library(stringr)
this.dir <- dirname(parent.frame(2)$ofile)
setwd(this.dir)
data <- read.table("D:\\GC Analysis\\gc.log-node1",sep="\n")
parse.mean <- function(){
fullgc.timestamp( fullgc.read() )
}
# Grep Full GC lines
fullgc.read <- function(){
return (data$V1[ grep ("(.*)Full GC(.*)", data[,1])])
}
fullgc.data <- function(timedata,memorydata){
memorydata["Time"] <- "NA"
memorydata$Time <- unlist(timedata)
return (fixdate(memorydata))
}
fullgc.timestamp <- function(input){
time <- str_extract(input,"T[^.]*")
timeframex<-data.frame(time)
timeframey<-subset(timeframex, timeframex[1] != "NA")
timeframey<-substring(timeframey$time,2,9)
timeframey <- data.frame(timeframey)
colnames( timeframey ) <- c("Time")
return (timeframey)
}
fullgc.memorypool.mean <- function(input){
data <- str_extract(input,"PSYou.*[/)]")
data <- str_extract_all(data,"[0-9]+")
data <- data.frame(matrix(unlist(data),ncol=12,byrow=T))
colnames(data)[2] <- c("YoungGenAfterFullGC")
colnames(data)[8] <- c("OldGenAfterFullGC")
colnames(data)[11] <- c("PermGenAfterFullGC")
return (data)
}
fixdate <- function(filtereddata){
filtereddata$Time1<-strptime(filtereddata$Time,"%H:%M:%S")
offset<-86400
lasttime<-filtereddata$Time1[1]
filtereddata$Time1[1]<-filtereddata$Time1[1]+offset
lasttime<-filtereddata$Time1[1]
for(timedate in 2:length(filtereddata$Time1)) {
if(as.numeric(filtereddata$Time1[timedate]) < lasttime){
offset<- offset + 86400
}
filtereddata$Time1[timedate]<-filtereddata$Time1[timedate]+offset
lasttime<-filtereddata$Time1[timedate]
}
return(filtereddata)
}
fullgc.youngandoldgen.graph <- function(filtereddata){
print(filtereddata)
png(
"younggenrecommendation.png",
width =1700, height = 510)
options("scipen"=100, "digits"=4)
plot( filtereddata$Time1,
levels(filtereddata$YoungGenAfterFullGC)[filtereddata$YoungGenAfterFullGC],
col="darkblue",type="l",
ylab="MB",
xlab="",
las=2,
lwd=5.5,
cex.lab=1,
cex.axis=0.8,
xaxt="n",
ylim=c(min(as.numeric(levels(filtereddata$OldGenAfterFullGC)[filtereddata$OldGenAfterFullGC])),
max(as.numeric(levels(filtereddata$OldGenAfterFullGC)[filtereddata$OldGenAfterFullGC]))))
axis(1, at = as.numeric(filtereddata$Time1), labels = filtereddata$Time, las = 2,cex.axis=1.2)
mtext("Time", side=1, line=-1, cex=1.3)
abline(h=mean(as.numeric(levels(filtereddata$OldGenAfterFullGC)[filtereddata$OldGenAfterFullGC])),col="yellow")
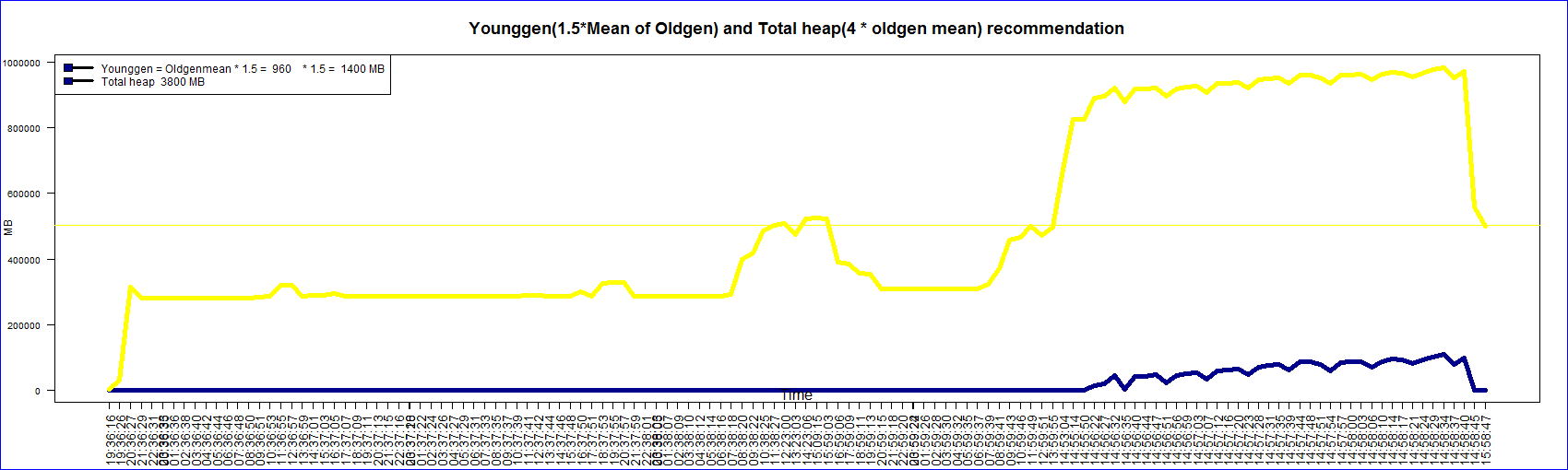
title("Younggen(1.5*Mean of Oldgen) and Total heap(4 * oldgen mean) recommendation",cex.main=1.5)
box("figure", col="blue")
points( filtereddata$Time1,
levels(filtereddata$OldGenAfterFullGC)[filtereddata$OldGenAfterFullGC],
col="yellow",
las=2,
lwd=5.5,
type="l")
legend("topleft", lty=c(1,1),lwd=c(3.5,3.5),
c(paste("Younggen = Oldgenmean * 1.5 = ",
signif(mean(as.numeric(levels(filtereddata$OldGenAfterFullGC)[filtereddata$OldGenAfterFullGC]))/1048*2,digits=2)," "," * 1.5 = ",
signif((mean(as.numeric(levels(filtereddata$OldGenAfterFullGC)[filtereddata$OldGenAfterFullGC]))/1048*2)*1.5,digits=2),"MB"),
paste("Total heap ",signif((mean(as.numeric(levels(filtereddata$OldGenAfterFullGC)[filtereddata$OldGenAfterFullGC]))/1048*2)*4,digits=2),"MB")),
fill=c("darkblue"))
dev.off()
}
fullgc.permandoldgen.graph <- function(filtereddata){
png(
"permgenrecommendation.png",
width =1700, height = 510)
options("scipen"=100, "digits"=4)
plot( filtereddata$Time1,
levels(filtereddata$PermGenAfterFullGC)[filtereddata$PermGenAfterFullGC],
col="darkblue",type="l",
ylab="MB",
xlab="",
las=2,
lwd=5.5,
cex.lab=1,
cex.axis=0.8,
xaxt="n",
ylim=c(min(as.numeric(levels(filtereddata$OldGenAfterFullGC)[filtereddata$OldGenAfterFullGC])),
max(as.numeric(levels(filtereddata$OldGenAfterFullGC)[filtereddata$OldGenAfterFullGC]))))
axis(1, at = as.numeric(filtereddata$Time1), labels = filtereddata$Time, las = 2,cex.axis=1.2)
mtext("Time", side=1, line=-1, cex=1.3)
abline(h=mean(as.numeric(levels(filtereddata$OldGenAfterFullGC)[filtereddata$OldGenAfterFullGC])),col="yellow")
abline(h=mean(as.numeric(levels(filtereddata$PermGenAfterFullGC)[filtereddata$PermGenAfterFullGC])),col="darkblue")
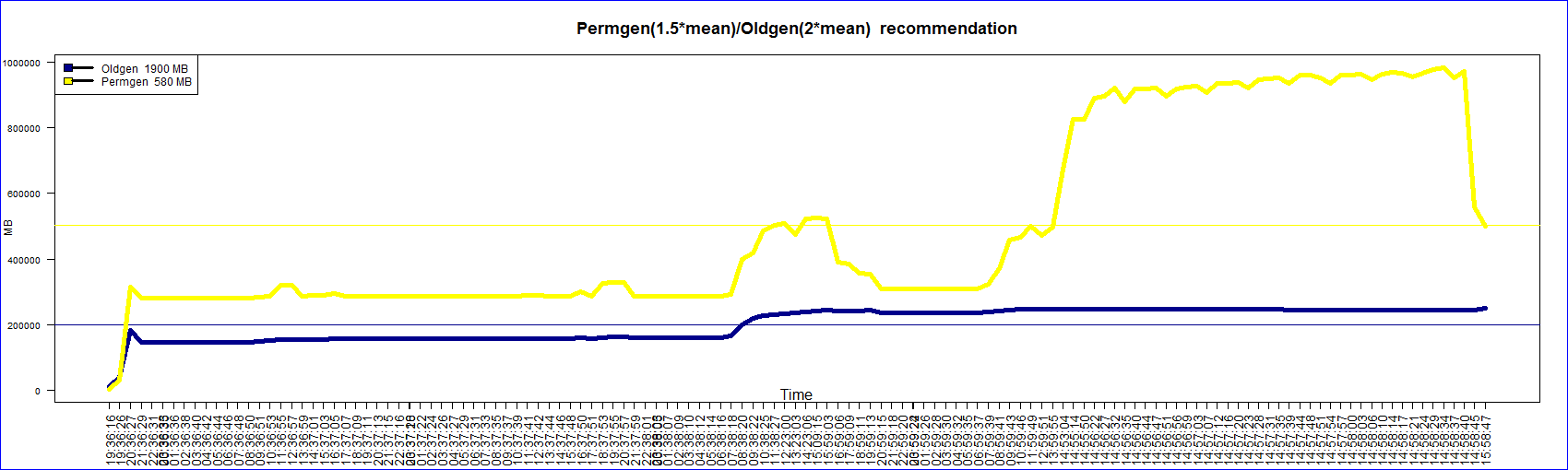
title("Permgen(1.5*mean)/Oldgen(2*mean) recommendation",cex.main=1.5)
box("figure", col="blue")
points( filtereddata$Time1,
levels(filtereddata$OldGenAfterFullGC)[filtereddata$OldGenAfterFullGC],
col="yellow",
las=2,
lwd=5.5,
type="l")
legend("topleft", lty=c(1,1),lwd=c(3.5,3.5),
c(paste("Oldgen ",signif((mean(as.numeric(levels(filtereddata$OldGenAfterFullGC)[filtereddata$OldGenAfterFullGC]))/1048*2)*2,digits=2),"MB"),
paste("Permgen ",signif((mean(as.numeric(levels(filtereddata$PermGenAfterFullGC)[filtereddata$PermGenAfterFullGC]))/1048*2)*1.5,digits=2),"MB")),
fill=c("darkblue","yellow"))
dev.off()
}
November 13, 2013 Leave a comment
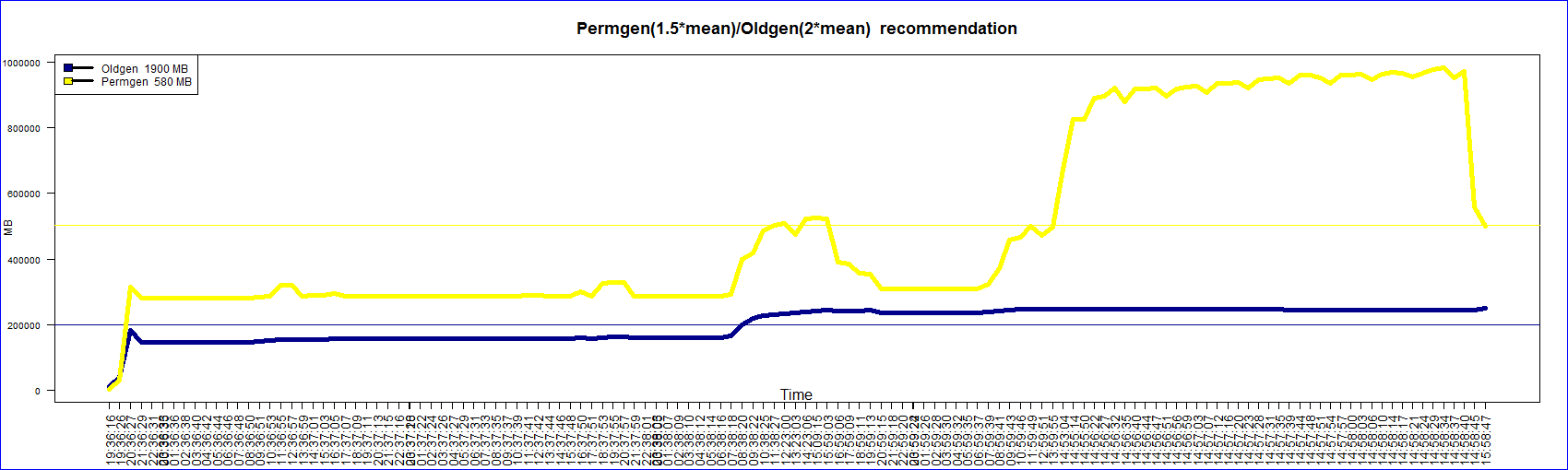
This graphs is generated from the garbage collection logs using ‘R’. The legend shows the general
recommendation based on the mean occupancy(Charlie Hunt’s book on Java performance).
Some values of time in the x-axis are too close together for reasons that I couldn’t understand. My previous blog entry has the old code and graph. I will post the modified code.
November 12, 2013 Leave a comment
I know that I am publishing ‘R’ code like this in a hurry. But I plan to add more explanations later on. The comments in the code are missing.
I obtain garbage collection log from a production JVM and isolate the ‘Full GC’ lines. The goal is to draw graphs of utilization and find the mean and recommend a size for the memory pools. I refer to Charlie Hunt’s book on Java Performance.
2013-10-04T19:36:16.497+0530: 2.152: [GC [PSYoungGen: 65537K->3456K(382272K)] 65537K->3456K(1256128K), 0.0090610 secs] [Times: user=0.04 sys=0.00, real=0.00 secs]
2013-10-04T19:36:16.506+0530: 2.161: [Full GC (System) [PSYoungGen: 3456K->0K(382272K)] [PSOldGen: 0K->3285K(873856K)] 3456K->3285K(1256128K) [PSPermGen: 12862K->12862K(25984K)], 0.0512630 secs] [Times: user=0.05 sys=0.00, real=0.06 secs]
2013-10-04T19:36:25.830+0530: 11.485: [GC [PSYoungGen: 327680K->22711K(382272K)] 330965K->25997K(1256128K), 0.0234720 secs] [Times: user=0.15 sys=0.02, real=0.02 secs]
2013-10-04T19:36:26.910+0530: 12.565: [GC [PSYoungGen: 84665K->28038K(382272K)] 87950K->31324K(1256128K), 0.0214230 secs] [Times: user=0.20 sys=0.03, real=0.02 secs]
2013-10-04T19:36:26.931+0530: 12.586: [Full GC (System) [PSYoungGen: 28038K->0K(382272K)] [PSOldGen: 3285K->30437K(873856K)] 31324K->30437K(1256128K) [PSPermGen: 39212K->39212K(69504K)], 0.2616280 secs] [Times: user=0.25 sys=0.01, real=0.26 secs]
2013-10-04T19:36:39.614+0530: 25.269: [GC [PSYoungGen: 327680K->15462K(382272K)] 358117K->45900K(1256128K), 0.0361220 secs] [Times: user=0.34 sys=0.00, real=0.03 secs]
2013-10-04T19:36:45.141+0530: 30.796: [GC [PSYoungGen: 343142K->30879K(382272K)] 373580K->61317K(1256128K), 0.1013610 secs] [Times: user=1.30 sys=0.00, real=0.10 secs]
library(stringr)
this.dir <- dirname(parent.frame(2)$ofile)
setwd(this.dir)
data <- read.table("D:\\GC Analysis\\gc.log-node1",sep="\n")
#print(data)
parse.mean <- function(){
fullgc.timestamp( fullgc.read() )
}
# Grep Full GC lines
fullgc.read <- function(){
return (data$V1[ grep ("(.*)Full GC(.*)", data[,1])])
}
fullgc.data <- function(timedata,memorydata){
memorydata["Time"] <- "NA"
memorydata$Time <- unlist(timedata)
return (memorydata)
}
fullgc.timestamp <- function(input){
time <- str_extract(input,"T[^.]*")
timeframex<-data.frame(time)
timeframey<-subset(timeframex, timeframex[1] != "NA")
timeframey<-substring(timeframey$time,2,9)
timeframey <- data.frame(timeframey)
colnames( timeframey ) <- c("Time")
return (timeframey)
}
fullgc.oldgen.mean <- function(input){
data <- str_extract(input,"PSOld.*[/)]")
data <- str_extract_all(data,"[0-9]+")
data <- data.frame(matrix(unlist(data),ncol=9,byrow=T))
colnames(data)[5] <- c("OldGenAfterFullGC")
colnames(data)[8] <- c("PermGenAfterFullGC")
return (data)
}
subset.removezerohours <- function( input ){
return( subset(input,as.POSIXlt(strptime(input$Time,"%H:%M:%S"))$hour != 0))
}
fullgc.permgen.graph <- function(filtereddata){
png(
"permgenrecommendation.png",
width =1720, height = 490)
filtereddata$Time1<-strptime(filtereddata$Time,"%H:%M:%S")
print(filtereddata)
offset<-86400
lasttime<-filtereddata$Time1[1]
filtereddata$Time1[1]<-filtereddata$Time1[1]+offset
lasttime<-filtereddata$Time1[1]
for(timedate in 2:length(filtereddata$Time1)) {
if(as.numeric(filtereddata$Time1[timedate]) < lasttime){
offset<- offset + 86400
}
filtereddata$Time1[timedate]<-filtereddata$Time1[timedate]+offset
lasttime<-filtereddata$Time1[timedate]
}
plot( filtereddata$Time1,
levels(filtereddata$PermGenAfterFullGC)[filtereddata$PermGenAfterFullGC],
col="darkblue",type="l",
ylab="MB",
xlab="",
las=2,
lwd=5.5,
cex.lab=1,
cex.axis=1,
xaxt="n")
axis(1, at = as.numeric(filtereddata$Time1), labels = filtereddata$Time, las = 2,cex.axis=1.3)
mtext("Time", side=1, line=-1, cex=1.3)
title("Permgen mean and recommendation",cex.main=1.5)
dev.off()
}

