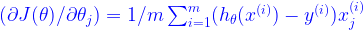A randomized divide-and-conquer algorithm
May 26, 2014 1 Comment
There is nothing new here. My Java code to find the 
I am using Google guava here.
Ints.toArray( less )
This is the algorithm definition.

import com.google.common.primitives.Ints;
import java.util.ArrayList;
import java.util.Random;
import static java.util.Arrays.sort;
public class KThLargestSelection {
private Random r = new Random();
static int[] a1 = new int[]{ 0,2,7,3,4,9};
public int findKThLargest( int[] a, int k ){
int pivot = getPivot(a);
ArrayList<Integer> less = new ArrayList<>();
ArrayList<Integer> equal = new ArrayList<>();
ArrayList<Integer> great = new ArrayList<>();
for( int value : a ){
if ( value < pivot){
less.add( value );
} else if ( value == pivot){
equal.add( value );
}else if ( value > pivot){
great.add( value );
}
}
if (k <= less.size()) {
return findKThLargest (Ints.toArray( less ), k);
}else if (k <= less.size() + equal.size()){
return pivot;
}else
return findKThLargest (Ints.toArray( great ), k - less.size() - equal.size());
}
private int getPivot( int[] data ){
int[] highLow = new int[0];
System.out.println("getPivot [" + data.length + "] " + toStringArray(data));
highLow = new int[] { data[0],data[data.length - 1] };
if( data.length >= 3){
sort(new int[]{data[r.nextInt(2)],
data[r.nextInt(2)],
data[r.nextInt(2)]});
}
return highLow[ 1 ];
}
private String toStringArray(int[] data){
StringBuilder sb = new StringBuilder();
for( int i = 0 ; i < data.length ; i ++ ){
sb.append( data[i] + " ");
}
return sb.toString();
}
public static void main( String... s){
KThLargestSelection l = new KThLargestSelection();
System.out.println( l.findKThLargest(a1, 1));
}
}



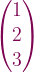



 . Furthermore, let
. Furthermore, let 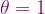 and
and  . You use the formula
. You use the formula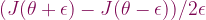
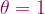 ,the true, exact derivative is
,the true, exact derivative is ).
).![J(\theta) = 1/m \sum_{i=1}^{m}[-y^{(i)} log( h_\theta(x^{(i)}) - (1-y^{(i)})log( 1 - h_\theta(x^{(i)}))] ;](https://s0.wp.com/latex.php?latex=J%28%5Ctheta%29+%3D+1%2Fm+%5Csum_%7Bi%3D1%7D%5E%7Bm%7D%5B-y%5E%7B%28i%29%7D+log%28+h_%5Ctheta%28x%5E%7B%28i%29%7D%29+-+%281-y%5E%7B%28i%29%7D%29log%28+1+-+h_%5Ctheta%28x%5E%7B%28i%29%7D%29%29%5D+%3B&bg=ffffff&fg=0000ff&s=1&c=20201002)