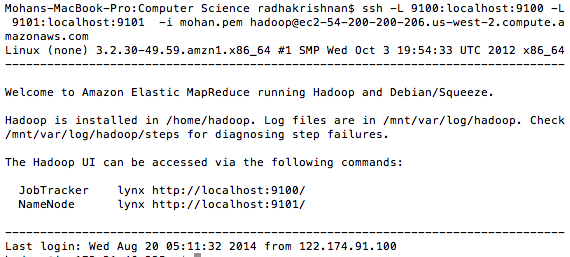
Python vs Java Streams and lambda
August 30, 2014 5 Comments
I ported the first facebook Qualification Round Solution to Java 8.
The main idea is to count the frequency of each letter, then assign the value 26 to the most frequent letter, 25 to the next, etc. If two letters are tied for most frequent, it doesn’t matter which of them gets which value, since the sum will be the same. The python code below explains the solution pretty well.
I haven’t thoroughly checked for bugs but this is almost as beautiful as Python. Java is more verbose though.
I haven’t tested it thoroughly though.
import java.util.Map;
import java.util.TreeMap;
import java.util.stream.IntStream;
public class WordCount {
public int x = 26;
public static void main(String... argv){
WordCount wc = new WordCount();
wc.count();
}
private void count() {
String s = "__mainn__".replaceAll("[^a-z\\s]", "");
System.out.println(s);
final Map<Character, Integer> count = s.chars().
map(Character::toLowerCase).
collect(TreeMap::new, (m, c) -> m.merge((char) c, 1, Integer::sum), Map::putAll);
count.entrySet().stream().
sorted((l, r) -> r.getValue().compareTo(l.getValue())).
forEach(e -> count.merge(e.getKey(), x--, Math::multiplyExact));
//Stop when x == 0.Not tested
System.out.println(count.entrySet().stream().mapToDouble(e -> e.getValue()).sum());
//Treating these numbers as double to sum them. Doesn't seem to matter.
}
}
mainn
a-1
i-1
m-1
n-2
{a=25, i=24, m=23, n=52}
124.0