Gradient Descent
October 6, 2015 Leave a comment
I ported the Gradient Descent code from Octave to Python. The base Octave code is the one from Andrew Ng’s Machine Learning MOOC.
I mistakenly believed that the Octave code for matrix multiplication will directly translate in Python.
The matrices are these.

But the Octave code is this
Octave code
theta = theta - ( ( alpha * ( (( theta' * X' )' - y)' * X ))/length(y) )'
and the Python code is this.
Python
def gradientDescent( X,
y,
theta,
alpha = 0.01,
num_iters = 1500):
r,c = X.shape
for iter in range( 1, num_iters ):
theta = theta - ( ( alpha * np.dot( X.T, ( np.dot( X , theta ).T - np.asarray(y) ).T ) ) / r )
return theta
This line is not a direct transalation.
theta = theta - ( ( alpha * np.dot( X.T, ( np.dot( X , theta ).T - np.asarray(y) ).T ) ) / r )
But only the above Python code gives me the correct theta that matches the value given by the Octave code.

Linear Regression
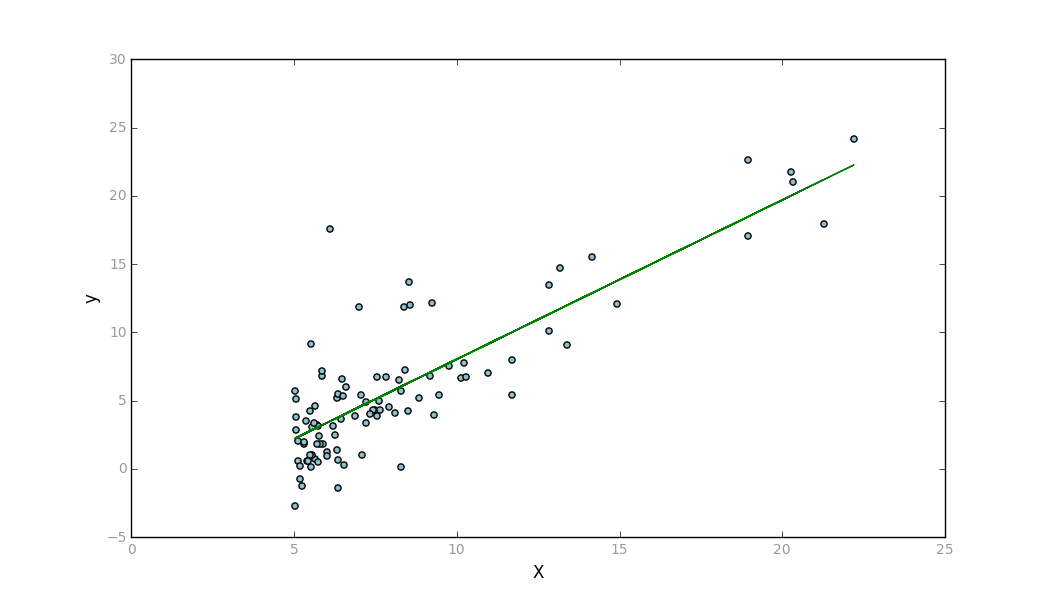
But the gradient descent also does not give me the correct value after a certain number of iterations. But the cost value is similar.
Gradient Descent from Octave Code that converges
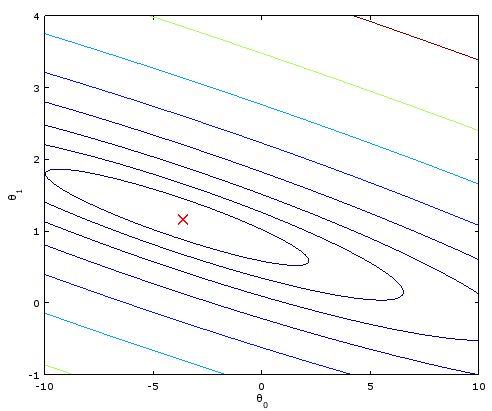
Minimization of cost
Initial cost is 640.125590
J = 656.25
Initial cost is 656.250475
J = 672.58
Initial cost is 672.583001
J = 689.12
Initial cost is 689.123170
J = 705.87
Initial cost is 705.870980
J = 722.83
Initial cost is 722.826433
J = 739.99
Initial cost is 739.989527
Gradient Descent from my Python Code that does not converge to the optimal value

Minimization of cost
635.81837438
651.963633303
668.316534159
684.877076945
701.645261664
718.621088313
735.804556895
