Microsoft: Data Science and Machine Learning Essentials
October 23, 2015 2 Comments
 After completing this edX course successfully I identified these questions which I answered wrongly. In some cases I selected more than the required options due to oversight.
After completing this edX course successfully I identified these questions which I answered wrongly. In some cases I selected more than the required options due to oversight.
I have marked the likely answers.
I need a longer article to explain what I learnt which I plan to write soon.
You have amassed a large volume of customer data, and want to determine if it is possible to identify distinct categories of customer based on similar characteristics.
What kind of predictive model should you create?
1. Regression
2. Clustering
3. Recommender
4. Classification
You discover that there are missing values for an unordered numeric column in your data.
Which three approaches can you consider using to treat the missing values?
1. Substitute the text “None”.
2. Forward fill or back fill the value.
3. Remove rows in which the value is missing.
4. Interpolate a value to replace the missing value.
5. Substitute the numeral 0
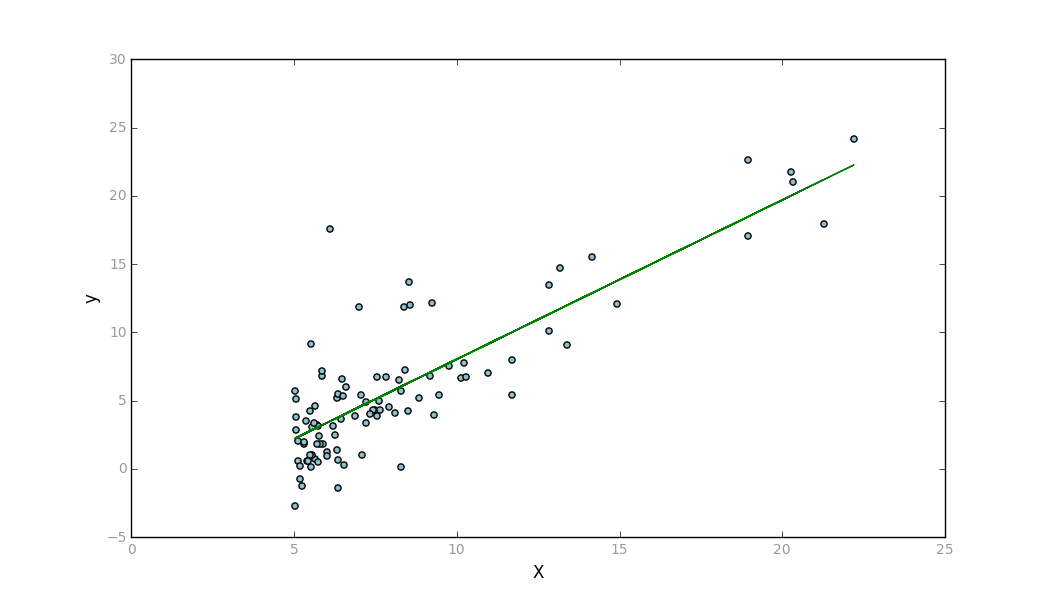
When assessing the residuals of a regression model you observe the following:
Residuals exhibit a persistent structure and are not randomly distributed with respect to values of the label or the features.
The Q-Q normal plots of the residuals show significant curvature and the presence of outliers.
Given these results, which two of the following things should you try to improve the model?
1. Cross validate the model to ensure that it will generalize properly.
2. Try a different class of regression model that might better fit the problem should be tried.
3. Create some engineered features with behaviors more closely tracking the values of the label.
4. Add a Sweep Parameters module with the Metric for measuring performance for classification property set to Accuracy.
You create an experiment that uses a Train Matchbox Recommender module to train a recommendation model, and add a Score Matchbox Recommender module to generate a prediction. You want to use the model in a music streaming service to recommend songs for the currently logged in user.Which recommender prediction kind should you configure the Score Matchbox
Recommender module to use?
1. Item Recommendation
2. Related Items
3. Rating Prediction
4. Related Users
While exploring a dataset you discover a nonlinear relationship between certain features and the label.Which two of the following feature engineering steps should you try before training a supervised machine learning model?
1. Ensure the features are linearly independent.
2. Compute new features based on polynomial values of the original features.
3. Compute mathematical combinations of the label and other features.
4. Compute new features based on logarithms or exponentiation of these original features.
Which two of the following approaches can you use to determine which features to prune in an Azure ML experiment?
1. Use the Permutation Feature Importance model to identify features of near-zero importance.
2. Use the Cross Validation module to identify folds which indicate the model does not generalize well.
3. Prune features one at a time to find features which reduce model performance or have no impact on model performance as measured with the Evaluate Model module.
4. Use the Split module to create training, test and evaluation data sub-sets to evaluate model performance.