Red-Black Tree
May 29, 2014 Leave a comment
I will refine this post as I code more methods. This is an attempt to learn this data structure and explain what I think I understand using pictures drawn using TEX. I use the tikz editor.
The algorithm code is based on pseudo-code from “Introduction to Algorithms” by Thomas H. Cormen et al. I use Java language features like enums etc. wherever possible.
Sample TEX code
[->,>=stealth',level/.style={sibling distance = 5cm/#1,
level distance = 1.5cm}]
\node [arn_n] {3}
child{ node [arn_r] {2}
child{ node [arn_nil] {NIL}}
}
child{ node [arn_r] {4}
child{ node [arn_nil] {NIL}}
}
;
Insert
public class RedBlack {
private final Node SENTINEL= new Node();
private Node root= new Node();
public RedBlack() {
root = SENTINEL;
}
enum Color {
BLACK,
RED};
class Node{
public void setColor(Color color) {
this.color = color;
}
private Color color = Color.BLACK;
Node left,right,p;
int key;
}
public void insert( RedBlack tree,
Node z){
Node y = SENTINEL;
Node x = tree.root;
while( x != SENTINEL){
y = x;
if ( z.key < x.key){
x = x.left;
}else
x = x.right;
}
z.p = y;
if( y == SENTINEL){
tree.root = z;
}else if ( z.key < y.key){
z = y.left;
}else{
z = y.right;
}
z.left = z.right = SENTINEL;
z.setColor(Color.RED);
}
}
I check the colors like this.
public void inOrder(Node x){
if( x != SENTINEL){
inOrder(x.left);
System.out.println(x.key + "[" + x.color + "]");
inOrder(x.right);
}
}
Now this tree has to be fixed so that it conforms to the rules that govern a Red-Black tree. So I code a method to fix it. This method is based on the pseudo-code from the same book. But I think there is a bug which I haven’t found. This tree after it is fixed looks like this.
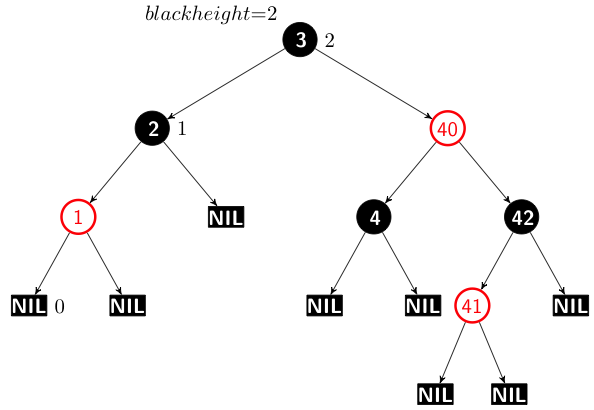
The black height property is 2.
The black height property for the left branch is 2 but it is 3 for one of the paths on the right.
I may have to read some other book because finding this bug is going to be hard.
Actually the tree should be like this.
 smallest element in an array(Algorithms book by S. Dasgupta, C. H. Papadimitriou, and U. V. Vazirani). The code is written based on the pseudo-code.
smallest element in an array(Algorithms book by S. Dasgupta, C. H. Papadimitriou, and U. V. Vazirani). The code is written based on the pseudo-code.